LINUX:Galera - Cluster de MariaDB
→ retour au menu des bases de données relationnelles
→ retour au menu de la Haute disponibilité
But
MariaDB possède une fonctionnalité qui permet qu'il travaille en cluster. Celle-ci est dénommée Galera. Cette fonctionnalité permet à plusieurs processus de MariaDB s'exécutant chacun sur des machines différentes et connectés à un réseau de travailler de concert; toute modification effectuée sur une des machine est répercutée sur les autres machines.
Matériel et adressage IP
Dans notre exemple, nous utilisons cinq serveurs. Le schéma ci-dessous nous montre l'adressage IP et le nom de ces trois machines.
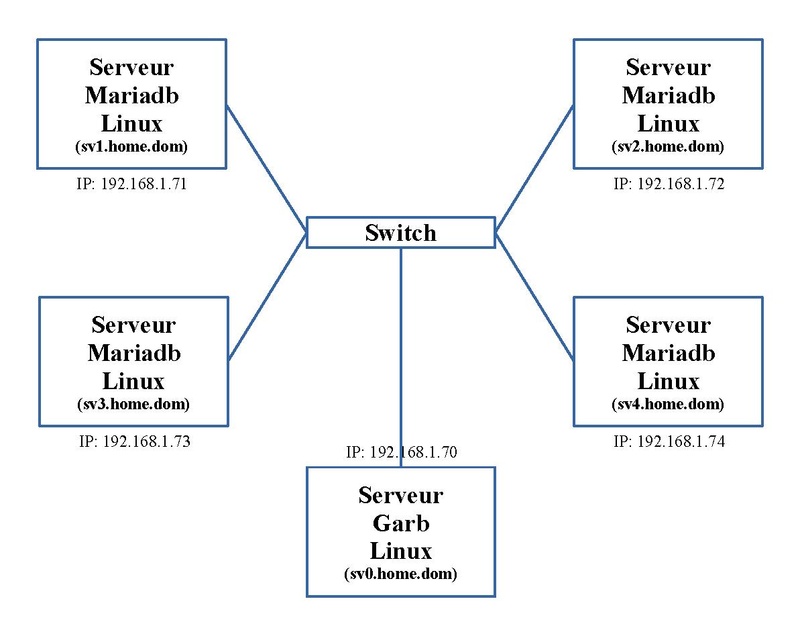
Les machines "sv1.home.dom", "sv2.home.dom", "sv3.home.dom" et "sv4.home.dom" vont exécuter chacune le service MariaDB ; la machine "sv0.home.dom" va exécuter le service Garb que nous verrons par la suite. L'ensemble de ces cinq machines constitue le cluster.
Prérequis
Sur les quatre premières machines, MariaDB doit être installé comme décrit dans l'article sur MariaDB: serveur de base de données. Attention: Ce service ne doit pas être activé!!!
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.70 sv0.home.dom 192.168.1.71 sv1.home.dom 192.168.1.72 sv2.home.dom 192.168.1.73 sv3.home.dom 192.168.1.74 sv4.home.dom # serveur mail 192.168.1.110 servermail.home.dom home.dom
Installation
La paquet de MariaDB Server doit être installé sur toutes les machines du cluster. Les dépendances nécessaires sont installées dans la foulée.
dnf install mariadb-server
Enfin on installe le paquet qui permet le clustering.
dnf install mariadb-server-galera
Le paquet Rsync doit être installé aussi sur toutes les machines du cluster:
dnf install rsync
Il permet de synchroniser la base de données qui démarre à partir une des occurrences du cluster de MariaDB active.
Configuration de MariaDB server
Comme expliqué dans l'article sur MariaDB: serveur de base de données, nous placerons les fichiers de la base de données dans le répertoire "/produc/mysql". Il faut créer ce répertoire et en donner la propriété et les privilèges à l'utilisateur "mysql":
mkdir /produc/mysql chown -R mysql:mysql /produc/mysql chmod -R 770 /produc/mysql
En conséquence, le fichier de configuration du serveur "/etc/my.cnf.d/mariadb-server.cnf" est à adapter; on modifie l'option suivante:
datadir=/produc/mysql
Cette configuration est à faire sur les quatre machines qui vont accueillir le service "mariadb.service".
Configuration de Galera
On passe à la configuration du cluster. Elle se trouvait dans le fichier "/etc/my.cnf.d/galera.cnf" mais depuis la nouvelle version, ce fichier n'est plus utilisé. Il faut donc mettre son contenu à la suite du fichier de configuration du serveur Mariadb, "/etc/my.cnf.d/mariadb-server.cnf".
Voici son contenu, concernant Galera, adapté à nos besoins:
[galera] innodb_force_primary_key = 1 binlog_format=ROW default-storage-engine=innodb innodb_autoinc_lock_mode=2 bind-address=0.0.0.0 wsrep_on = ON wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_name="Home_cluster" wsrep_cluster_address = "gcomm://192.168.1.70,192.168.1.71,192.168.1.72,192.168.1.73,192.168.1.74" #wsrep_node_address="192.168.1.71" wsrep_slave_threads=1 wsrep_certify_nonPK=1 wsrep_max_ws_rows=0 wsrep_max_ws_size=2147483647 wsrep_debug=0 wsrep_convert_LOCK_to_trx=0 wsrep_retry_autocommit=1 wsrep_auto_increment_control=1 wsrep_drupal_282555_workaround=0 wsrep_causal_reads=0 wsrep_notify_cmd=/produc/mysql.bat/mysql.bat wsrep_sst_method=rsync wsrep_sst_auth=root:
Les options modifiées sont mises en gras. Les autres options sont déjà contenues dans le fichier de configuration.
Explications de quelques options importantes:
- default-storage-engine=innodb : Il est nécessaire que les différents schémas utilisent le moteur Innodb.
- innodb_force_primary_key=1 : Il est fortement conseillé que toute table aie une clé primaire afin d'éviter la prolifération d'enregistrements en doublon inappropriés.
- wsrep_on=ON ou wsrep_on=1 : Il permet l'activation du mode cluster.
- wsrep_cluster_name="Home_cluster" : On donne un nom identifiant à notre cluster. Il est personnalisable.
- wsrep_cluster_address="gcomm://192.168.1.70,192.168.1.71,192.168.1.72,192.168.1.73,192.168.1.74" : Cette option est primordiale. Elle définit l'ensemble des machines du cluster (service Garb compris). On y retrouve les adresses IP de nos cinq machines.
- wsrep_notify_cmd=/produc/mysql.bat/mysql.bat : Cette option est facultative. Elle permet d'effectuer une action exécutée par le script défini à tout changement d'état du cluster reçu par la machine locale. Nous l'utiliserons par la suite pour être averti par mail en cas de connexion ou déconnexion d'un membre du cluster. Evidemment il faut que le service de messagerie par exemple Postfix soit activé.
- wsrep_node_address="192.168.1.71" : Cette option est facultative. Elle peut être nécessaire si la machine a plusieurs interfaces réseaux. Elle correspond à l'adresse IP de la machine concernée; dans notre exemple, elle est contenue dans le fichier de configuration de la machine "sv1.home.dom".
Cette configuration est à faire sur les quatre machines qui vont accueillir le service "mariadb.service".
Script de notification
Avec l'option "wsrep_notify_cmd", nous voulons faire appel à un script.
Pour le mettre en place, nous effectuons quelques opérations. En premier, on crée un répertoire "/produc/mysql.bat" et en donne la propriété et les privilèges à l'utilisateur "mysql":
mkdir /produc/mysql.bat chown -R mysql:mysql /produc/mysql.bat chmod -R 770 /produc/mysql.bat
Dans ce répertoire, on crée le fichier "mysql.bat" dont voici le contenu:
#!/bin/bash
CHEMIN=/produc/mysql.bat
cd ${CHEMIN}
CHAINE=$*
date >> $CHEMIN/mysql.lis
echo $CHAINE >> $CHEMIN/mysql.lis
HOST=`hostname`
STATUS=""
CLUSTER_UUID=""
PRIMARY=""
MEMBERS=""
INDEX=""
while [ $# -gt 0 ]
do
case $1 in
--status)
STATUS=$2
shift
;;
--uuid)
CLUSTER_UUID=$2
shift
;;
--primary)
PRIMARY=$2
shift
;;
--index)
INDEX=$2
shift
;;
--members)
MEMBERS=$2
shift
;;
esac
shift
done
MAIL=""
case $STATUS in
"joined")
if [ "$CLUSTER_UUID" != "" ]
then
MAIL="OK"
fi
;;
"disconnected")
if [ "$CLUSTER_UUID" != "" ]
then
MAIL="OK"
fi
;;
*)
MAIL="KO"
;;
esac
if [ "$MAIL" == "OK" ]
then
echo -n "Serveur - " > ${CHEMIN}/dfmail.log
hostname >> ${CHEMIN}/dfmail.log
echo " " >> ${CHEMIN}/dfmail.log
date >> ${CHEMIN}/dfmail.log
echo " " >> ${CHEMIN}/dfmail.log
echo "Mariadb: le cluster a changé d'état" >> ${CHEMIN}/dfmail.log
echo " " >> ${CHEMIN}/dfmail.log
echo "Statut: $STATUS" >> ${CHEMIN}/dfmail.log
echo "Membres: $MEMBERS" >> ${CHEMIN}/dfmail.log
echo "Index: $INDEX" >> ${CHEMIN}/dfmail.log
echo "Primary: $PRIMARY" >> ${CHEMIN}/dfmail.log
echo "UUID du cluster: $CLUSTER_UUID" >> ${CHEMIN}/dfmail.log
# echo $CHAINE >> ${CHEMIN}/dfmail.log
/bin/mail -s "Mariadb-Galera: $HOST" root < ${CHEMIN}/dfmail.log
/usr/bin/rm -f ${CHEMIN}/dfmail.log
fi
Ce script va envoyer un mail quand une machine entre (se connecte) ou sort (se déconnecte) du cluster.
Ceci est un exemple à adapter selon vos besoins.
Utilisation de Garb
Le cluster doit toujours être constitué d'un nombre impaire de machines car s'il était en nombre pair, deux groupes séparés d'un nombre égal de machines peuvent se constituer suite par exemple à des coupures réseaux. Il n'y aurait alors de de groupe majoritaire et chaque groupe pourrait évoluer séparément avec des bases de données ayant un contenu différents (Split-Brain). La présence d'un nombre pair de bases de données MariaDB peuvent se justifier pour une question de disponibilité de matériel ou d'utilisation finale.
Dans ce cas d'un nombre pair, il faut ajouter une composante additionnelle. Cette composante est le service Garb "garbd.service". Il participe aux échanges entre membres du cluster mais ne stocke aucune données; il n'y a aucun base de données présente. Si nous avons un nombre impaire de base de données Mariadb, le service Garb n'est pas nécessaire.
Configuration de Garb
La configuration de Garb se trouve dans le fichier "/etc/sysconfig/garb".
Voici son contenu:
GALERA_NODES="192.168.1.70,192.168.1.71,192.168.1.72,192.168.1.73,192.168.1.74" GALERA_GROUP="Home_cluster" LOG_FILE="/var/log/garb/garb.log"
On y retrouve deux des options définies dans le fichier de configuration de Galera "/etc/my.cnf.d/galera.cnf".
Les options suivantes:
- GALERA_NODES correspond au paramètre "wsrep_cluster_address"
- GALERA_GROUP correspond au paramètre "wsrep_cluster_name"
On a défini l'emplacement d'un fichier journal. Mais le répertoire concerné n'existe pas; il faut le créer et lui donner la propriété à l'utilisateur "garb" qui lance le service "garbd.service":
mkdir /var/log/garb chown -R garb:garb /var/log/garb
Dans le fichier de configuration par défaut, il existe l'option "WORK_DIR". Ne l'utilisez pas sinon le service entrera en erreur et ne se lancera pas; l'argument lié n'existe pas pour le processus "garbd". Or ce paramètre est utile si pas nécessaire pour pouvoir localiser le fichier d'état du cluster localement. Il faut donc trouver une astuce. Cette astuce passe par ajouter une option à Systemd.
Nous créons le sous-répertoire "garbd.service.d" dans le répertoire "/etc/systemd.system":
mkdir garbd.service.d
Dans ce répertoire, on crée un fichier qui permet d'ajouter une option définissant le répertoire de travail du service "garbd.service". On nomme ce fichier "workdir.conf" dont voici le contenu:
[Service] WorkingDirectory=/produc/garb
Comme on a modifié le paramétrage de Systemd, il faut le recharger:
systemctl daemon-reload
Il faut maintenant créer ce répertoire et lui donner la propriété à l'utilisateur "garb" qui lance le service "garbd.service":
mkdir /produc/garb chown -R garb:garb /produc/garb
Cette configuration est à faire sur la machine "sv0.home.dom" qui va accueillir le service "garbd.service".
Activation des services
Au contraire de ce qu'on fait habituellement, les services "mariadb.service" et "garbd.service" ne devront jamais être activés. Car dans le cas où toutes les machines sont arrêtées, le cluster n'existe plus. Il faut donc toujours réinitialiser le cluster sur la machine où le dernier service "mariadb.service" a été arrêté en dernier lieu et donc qui a la version de la base de données la plus récente. Dès que le cluster a été lancé, on peut alors lancer les services "mariadb.service" ou "garbd.service" sur les autres machines.
Configurer le mur de feu ou FireWall
MariaDB écoute sur le port TCP 3306 comme traité dans l'article sur MariaDB: serveur de base de données. Nous n'y reviendrons pas.
Par contre, la fonctionnalité Galera (Garb comprise) utilise toute une série de ports qu'il faut sécuriser.
- le port TCP 4444 permet au programme Rsync la synchronisation au démarrage
- les ports TCP et UDP 4567 permettent la réplication en cours d'utilisation entre les bases de données
- Le port TCP 4568 permet le transfert incrémental de l'état afin de rattraper son retard vis-à-vis de ses collègues
Ces transferts de passent exclusivement entre les machines du cluster.
Pour le FireWall Iptables, on ajoute les règles suivantes sur toutes les machines du cluster:
-A INPUT -p tcp -m tcp --dport 4444 -m iprange --src-range 192.168.1.70-192.168.1.74 -j ACCEPT -A INPUT -p tcp -m tcp --dport 4567 -m iprange --src-range 192.168.1.70-192.168.1.74 -j ACCEPT -A INPUT -p udp -m udp --dport 4567 -m iprange --src-range 192.168.1.70-192.168.1.74 -j ACCEPT -A INPUT -p tcp -m tcp --dport 4568 -m iprange --src-range 192.168.1.70-192.168.1.74 -j ACCEPT
Initialisation du cluster
La première étape est l'initialisation du cluster.
On choisit une des quatre machines devant héberger le service MariaDB, par exemple "sv1.home.dom". Sur cette machine on lance une première fois le service "mariadb.service":
systemctl start mariadb.service
et on le sécurise avec la commande:
mysql_secure_installation
On peut maintenant arrêter ce service:
systemctl stop mariadb.service
Il est inutile de lancer le service MariaDB sur les trois autres machines car la base de données résultante sera écrasée, perdue. A ce stade, il vaut mieux que le répertoire accueillant la base de données, ici "/produc/mysql", soit vide. On ne lance pas le service Garb car le cluster n'existe pas encore; il entrerait en erreur.
On lance le cluster avec la commande:
galera_new_cluster
En parcourant la liste des processus, on peut remarquer que le services "mariadb.service" est lancé. Pour l'arrêter, on peut utiliser la commande classique:
systemctl stop mariadb.service
A ce stade, ne le faites pas. Voyez l'avant dernier point de cet article pour plus d'explications.
Si on effectue la requête SQL suivante sur cette première machine en ligne de commande "mysql":
show status like 'wsrep_cluster_size';
on a le nombre actuel de membres dans le cluster:
+--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 1 | +--------------------+-------+ 1 row in set (0,001 sec)
Il est évidemment à "1" comme attendu.
Lancement du reste du cluster
Le premier service MariaDB est lancé et va servir de référence pour les autres. Dès lors on lance le service MariaDB sur les trois autres machines:
systemctl start mariadb.service
Ces trois machines vont tâcher de rentrer en relation avec la première machine de référence. Dès la connexion étable, la première étape consiste à la synchronisation; tout le contenu du répertoire de la base de données "/produc/mysql" (sauf deux) vont être copié sur les autres grâce au logiciel "rsync" via le port TCP 4444. Notons que si on effectue la synchronisation par étape; par exemple, si on synchronise la machine "sv2.home.dom", les deux machines restantes ("sv3.home.dom" et "sv4.home.dom") auront le choix entre ces deux premières machines ("sv1.home.dom" et "sv2.home.dom") comme référence.
Maintenant ces quatre machines sont synchronisées et pleinement actives.
En même temps ou après, on lance le service Garb "garbd.service" sur la dernière machine "sv0.home.dom":
systemctl start garbd.service
Maintenant si on effectue à nouveau la requête SQL suivante sur cette première machine en ligne de commande "mysql":
show status like 'wsrep_cluster_size';
On a le nombre actuel de membres dans le cluster:
+--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 5 | +--------------------+-------+ 1 row in set (0,001 sec)
Il est à "5". Tout c'est bien passé.
On peut sur chacune des quatre machines où le service MariaDB s'exécute, effectuer la requête SQL suivante sur cette première machine en ligne de commande "mysql":
show status like 'wsrep_local_state_comment';
Elle affiche l'état de cette instance, ici elle est synchronisée:
+---------------------------+--------+ | Variable_name | Value | +---------------------------+--------+ | wsrep_local_state_comment | Synced | +---------------------------+--------+ 1 row in set (0,001 sec)
Evolution du cluster
Toutes les machines du cluster sont actives.
Si on en arrête une des machines ou seulement le service concerné, le nombre de membres diminue d'une unité mais on peut redémarrer le service comme on le ferait normalement:
systemctl start mariadb.service
ou
systemctl start garbd.service
Après une courte étape de synchronisation "rsync", le service est de nouveau opérationnelle; la machine est de nouveau incluse dans le cluster. Il n'y a rien de spécial à faire.
Arrêt complet
Par contre si on arrête toutes les machines du cluster ou qu'on arrête tous les services concernés, le cluster Galera n'existe plus. On veille si possible de ne pas arrêter le service Garb ou sa machine en dernier lieu.
Quand on veut redémarrer le cluster, il faut procéder d'une façon spéciale.
Normalement c'est la dernière machine arrêtée ou son service qui est le plus à jour. C'est à partir de celle-ci qu'il faut redémarrer le cluster.
On peut le vérifier en consultant le fichier d'état du cluster "grastate.dat" se trouvant dans le répertoire de la base de données ("/produc/mysql"). Il contient diverses variables.
On repère la machine dont la variable "seqno" est la plus haute. Attention, si vous avez essayé sans succès de redémarrer le service MariaDB, cette valeur est mise à "-1", symptôme de crash. Dès que vous avez repéré la bonne machine, il faut que la variable "safe_to_bootstrap" de ce même fichier soit à "1" sinon le cluster ne redémarrera jamais. Si ce n'est pas le cas, on met cette valeur à "1" sur la machine choisie; ça peut être n'importe quelle machine. Si ce n'est pas la dernière arrêtée, vous risquez de perdre les dernières informations mises dans la base de données.
Sur cette machine choisie et dans cet état décrit ci-dessus, on relance la commande:
galera_new_cluster
Cette fois-ci, le démarrage est rapide.
Pour les autres machines, on procède comme normalement:
systemctl start mariadb.service
ou
systemctl start garbd.service
C'est pour cette raison que l'on n'active pas le lancement automatique des services "mariadb.service" et "garbd.service".
Si on était sûr qu'au moins une des quatre machines hébergeant le service MariaDB ne s'arrêtait jamais, on pourrait les activer mais on n'est pas à l'abri d'une longue coupure d'électricité ou d'une catastrophe.
Migration
Une des contraintes majeure pour passer d'une base de données isolée à une base de données en cluster est la "nécessité", du moins une forte recommandation, est que chaque table de chaque schéma possède une clé primaire.
Dans la pratique, nombre de schémas implantés avec des logiciels en sont équipées. Dans les autres cas, il faut analyser la situation. Pour ma part, j'ajoute un champs nommé "noid" à ces tables avec l'option "AUTO_INCREMENT" qui devient la clé primaire.
Quelques cas: Pour les logiciels WordPress, Cacti, NagioSQL, PhpMyAdmin, Piwigo, PostFix, il n'y a pas de problème. Par contre pour Mediawiki, il y a quelques tables qui nécessitent cette opération: "oldimage", "querycache", "querycachetwo" et "user_newtalk".
MariaDB/Galera - Solution d'automatisation de démarrage
Pour contourner cette limitation d'automatisation de démarrage du cluster Galera, j'ai créé deux services Systemd de type Timer, l'un pour MariaDB et l'autre pour Garb. Au lieu d'utiliser Systemd, on peut utiliser le système de Cron.
Commentaire
Cette configuration pourrait être combinée à celle présentée dans l'article sur Quatre serveurs WEB en Failover, Fsyncd et ISCSI.
→ retour au menu des bases de données relationnelles
→ retour au menu de la Haute disponibilité