LINUX:Glusterfs - Type Répliqué
→ retour au menu de Glusterfs - Gestion des serveurs
But
Ce second type répliqué correspond au RAID1. Les fichiers sont distribués sur les divers espaces disques individuels des machines du cluster. Chaque espace disque accueille tous les fichiers. Ils sont tous en doublons.
Notons que les commandes peuvent se faire à partir de n'importe quel serveur du cluster.
Réplication sur deux espaces disques
Ce premier exemple va créer un volume utilisant deux espaces disques individuels se trouvant sur deux machines.
Mise en place
La commande suivante crée un volume nommé "diskgfs3" sur les machines "sv1.home.dom" et "sv2.home.dom":
gluster volume create diskgfs3 replica 2 transport tcp sv1.home.dom:/disk1/glusterfs/brique3 sv2.home.dom:/disk1/glusterfs/brique3
Ici nous avons un message:
Replica 2 volumes are prone to split-brain. Use Arbiter or Replica 3 to avoid this. See: http://docs.gluster.org/en/latest/Administrator-Guide/Split-brain-and-ways-to-deal-with-it/. Do you still want to continue? (y/n)
En effet pour une question de "split-brain" car nous sommes en réseau, il est conseillé d'avoir au moins trois "replicas". Nous confirmons.
Sur chacune de ces machines, un sous-répertoire "brique3" est créé automatiquement sous le répertoire "/disk1/glusterfs". Je conseille fortement de ne pas créer ce répertoire "brique3" au préalable. Glusterfs va lui attribuer des droits spéciaux à ne pas modifier. Et en cas de réutilisation, vous aurez des problèmes. Pour une question de clarté, nous utilisons la même arborescence de répertoires.
Il y a une contrainte; si nous demandons deux "replica", il nous faut deux espaces disques individuels.
Le schéma ci-dessous illustre la réplication de 8 fichiers. Les huit sont placés sur la première machine et sur la seconde.
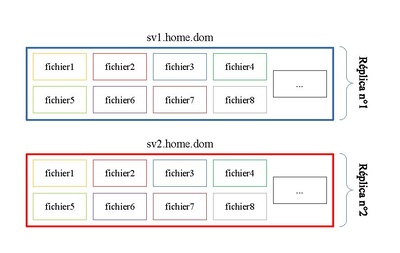
On remarque tout de suite que comme le système RAID1, si un disque entre en erreur, on ne perd pas ces fichiers.
Maintenant que ce volume est créé, il faut le démarrer pour le rendre accessible grâce à la commande suivante:
gluster volume start diskgfs3
Processus
En listant la liste des processus, on remarque que de nouveaux sont lancés.
ps axf | grep glusterfs
qui donne sur la machine "sv1.home.dom":
9716 ? SLsl 0:00 /usr/sbin/glusterfsd -s sv1.home.dom --volfile-id diskgfs3.sv1.home.dom.disk1-glusterfs-brique3 -p /var/run/gluster/vols/diskgfs3/sv1.home.dom-disk1-glusterfs-brique3.pid -S /var/run/gluster/59cfac74a3c16f5f.socket --brick-name /disk1/glusterfs/brique3 -l /var/log/glusterfs/bricks/disk1-glusterfs-brique3.log --xlator-option *-posix.glusterd-uuid=1ea22555-2c1b-40a9-8183-020b621c6d06 --process-name brick --brick-port 57603 --xlator-option diskgfs3-server.listen-port=57603 9748 ? SLsl 0:00 /usr/sbin/glusterfs -s localhost --volfile-id shd/diskgfs3 -p /var/run/gluster/shd/diskgfs3/diskgfs3-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/432231f833cff617.socket --xlator-option *replicate*.node-uuid=1ea22555-2c1b-40a9-8183-020b621c6d06 --process-name glustershd --client-pid=-6
On trouve deux processus: "glustersfd" et "glusterfs". On les retrouvera aussi sur l'autre serveur participant à ce volume "sv2.home.dom".
Mais sur les machines ne participant pas à ce volume, on trouve aussi un processus: "glusterfs"; ici sur "sv3.home.dom":
5984 ? SLsl 0:00 /usr/sbin/glusterfs -s localhost --volfile-id shd/diskgfs3 -p /var/run/gluster/shd/diskgfs3/diskgfs3-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/89c1a2ecea747dc4.socket --xlator-option *replicate*.node-uuid=27bd8184-14c8-4176-987d-db0a03fc6993 --process-name glustershd --client-pid=-6
Connexions réseaux
Au niveau réseau, un nouveau port est à l'écoute lancé par ce processus "glusterfsd" et des interconnexions sont faites avec toutes les autres machines du cluster. D'autres interconnexions sont faites entre les machines concernées par le volume; les processus "glustersfd" et "glusterfs" et le service "glusterd.service" sont concernés:
netstat -natp | grep gluster
qui donne par différence sur la machine "sv1.home.dom" pour le premier volume:
tcp 0 0 0.0.0.0:57603 0.0.0.0:* LISTEN 9716/glusterfsd tcp 0 0 192.168.1.71:57603 192.168.1.71:49145 ESTABLISHED 9716/glusterfsd tcp 0 0 192.168.1.71:57603 192.168.1.72:49145 ESTABLISHED 9716/glusterfsd tcp 0 0 192.168.1.71:57603 192.168.1.73:49146 ESTABLISHED 9716/glusterfsd tcp 0 0 192.168.1.71:57603 192.168.1.74:49146 ESTABLISHED 9716/glusterfsd tcp 0 0 192.168.1.71:57603 192.168.1.75:49146 ESTABLISHED 9716/glusterfsd tcp 0 0 192.168.1.71:57603 192.168.1.76:49150 ESTABLISHED 9716/glusterfsd tcp 0 0 127.0.0.1:24007 127.0.0.1:49145 ESTABLISHED 1215/glusterd tcp 0 0 127.0.0.1:49145 127.0.0.1:24007 ESTABLISHED 9748/glusterfs tcp 0 0 192.168.1.71:24007 192.168.1.71:49146 ESTABLISHED 1215/glusterd tcp 0 0 192.168.1.71:49141 192.168.1.72:53502 ESTABLISHED 9748/glusterfs tcp 0 0 192.168.1.71:49145 192.168.1.71:57603 ESTABLISHED 9748/glusterfs tcp 0 0 192.168.1.71:49146 192.168.1.71:24007 ESTABLISHED 9716/glusterfsd
Cette situation est identique sur l'autre machine impliquée dans ce volume; "sv2.home.dom".
Mais sur les machines ne participant pas à ce volume, on trouve aussi des interconnexions; ici sur "sv3.home.dom":
tcp 0 0 127.0.0.1:24007 127.0.0.1:49146 ESTABLISHED 801/glusterd tcp 0 0 127.0.0.1:49146 127.0.0.1:24007 ESTABLISHED 5984/glusterfs tcp 0 0 192.168.1.73:49143 192.168.1.72:53502 ESTABLISHED 5984/glusterfs tcp 0 0 192.168.1.73:49146 192.168.1.71:57603 ESTABLISHED 5984/glusterfs
Il faudra en tenir compte dans le Firewall. Mais ces nouveaux ports TCP sont très aléatoires.
Statut
Les informations ci-dessus peuvent être obtenues grâce à la commande suivante pour le volume "diskgfs3":
gluster volume status diskgfs3
qui donne:
Status of volume: diskgfs3 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick sv1.home.dom:/disk1/glusterfs/brique3 57603 0 Y 9716 Brick sv2.home.dom:/disk1/glusterfs/brique3 53502 0 Y 5538 Self-heal Daemon on localhost N/A N/A Y 9748 Self-heal Daemon on sv4.home.dom N/A N/A Y 5377 Self-heal Daemon on sv3.home.dom N/A N/A Y 5984 Self-heal Daemon on sv2.home.dom N/A N/A Y 5570 Self-heal Daemon on sv5.home.dom N/A N/A Y 4212 Self-heal Daemon on sv6.home.dom N/A N/A Y 9397 Task Status of Volume diskgfs3 ------------------------------------------------------------------------------ There are no active volume tasks
D'autres informations peuvent être obtenues:
gluster volume info diskgfs3
qui donne:
Volume Name: diskgfs3 Type: Distributed-Replicate Volume ID: 157d711a-fa5b-4b36-816e-a519aab633c0 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: sv1.home.dom:/disk1/glusterfs/brique3 Brick2: sv2.home.dom:/disk1/glusterfs/brique3 Options Reconfigured: cluster.granular-entry-heal: on storage.fips-mode-rchecksum: on transport.address-family: inet nfs.disable: on performance.client-io-threads: off
On y remarque le type et le nombre de briques. Le type est combiné Distribué et Répliqué mais la partie Distribuée est simple ("1") donc non utilisée.
Réplication sur trois espaces disques
Ce second exemple va créer un volume utilisant trois espaces disques individuels se trouvant sur trois machines.
Mise en place
La commande suivante crée un volume nommé "diskgfs4" sur les machines "sv3.home.dom", "sv4.home.dom" et "sv5.home.dom":
gluster volume create diskgfs4 replica 3 transport tcp sv3.home.dom:/disk1/glusterfs/brique4 sv4.home.dom:/disk1/glusterfs/brique4 \
sv5.home.dom:/disk1/glusterfs/brique4
Sur chacune de ces machines, un sous-répertoire "brique4" est créé automatiquement sous le répertoire "/disk1/glusterfs".
Le schéma ci-dessous illustre la répartition de 8 fichiers. Les huit sont placés sur chacune des trois machines.
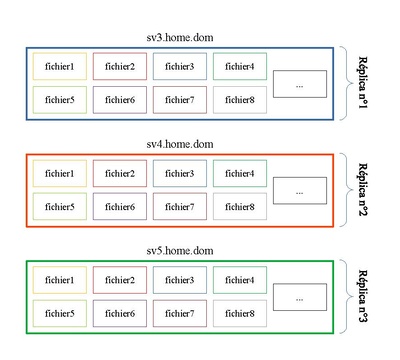
On remarque tout de suite que comme le système RAID1, si un disque entre en erreur, on ne perd pas ces fichiers. Nous n'avons plus le message rencontré précédemment concernant le "split-brain".
Maintenant que ce volume est créé, il faut le démarrer pour le rendre accessible grâce à la commande suivante:
gluster volume start diskgfs4
Processus
En listant la liste des processus, on remarque que de nouveaux sont lancés.
ps axf | grep glusterfs
qui donne sur la machine "sv3.home.dom":
6072 ? SLsl 0:00 /usr/sbin/glusterfsd -s sv3.home.dom --volfile-id diskgfs4.sv3.home.dom.disk1-glusterfs-brique4 -p /var/run/gluster/vols/diskgfs4/sv3.home.dom-disk1-glusterfs-brique4.pid -S /var/run/gluster/6ce5fcbef1e29ecc.socket --brick-name /disk1/glusterfs/brique4 -l /var/log/glusterfs/bricks/disk1-glusterfs-brique4.log --xlator-option *-posix.glusterd-uuid=27bd8184-14c8-4176-987d-db0a03fc6993 --process-name brick --brick-port 59730 --xlator-option diskgfs4-server.listen-port=59730 6104 ? SLsl 0:00 /usr/sbin/glusterfs -s localhost --volfile-id shd/diskgfs4 -p /var/run/gluster/shd/diskgfs4/diskgfs4-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/9f7e18bc15b075d5.socket --xlator-option *replicate*.node-uuid=27bd8184-14c8-4176-987d-db0a03fc6993 --process-name glustershd --client-pid=-6
On trouve deux processus: "glustersfd" et "glusterfs". On les retrouvera aussi sur les autres serveurs participant à ce volume "sv4.home.dom" et "sv5.home.dom".
Mais sur les machines ne participant pas à ce volume, on trouve aussi un processus: "glusterfs"; ici sur "sv1.home.dom":
9869 ? SLsl 0:00 /usr/sbin/glusterfs -s localhost --volfile-id shd/diskgfs4 -p /var/run/gluster/shd/diskgfs4/diskgfs4-shd.pid -l /var/log/glusterfs/glustershd.log -S /var/run/gluster/c6fefa88d78ddd6f.socket --xlator-option *replicate*.node-uuid=1ea22555-2c1b-40a9-8183-020b621c6d06 --process-name glustershd --client-pid=-6
Connexions réseaux
Au niveau réseau, un nouveau port est à l'écoute lancé par ce processus "glusterfsd" et des interconnexions sont faites avec toutes les autres machines du cluster. D'autres interconnexions sont faites entre les machines concernées par le volume; les processus "glustersfd" et "glusterfs" et le service "glusterd.service" sont concernés:
netstat -natp | grep gluster
qui donne par différence sur la machine "sv3.home.dom" pour le premier volume:
tcp 0 0 0.0.0.0:59730 0.0.0.0:* LISTEN 6072/glusterfsd tcp 0 0 192.168.1.73:59730 192.168.1.71:49139 ESTABLISHED 6072/glusterfsd tcp 0 0 192.168.1.73:59730 192.168.1.72:49146 ESTABLISHED 6072/glusterfsd tcp 0 0 192.168.1.73:59730 192.168.1.73:49145 ESTABLISHED 6072/glusterfsd tcp 0 0 192.168.1.73:59730 192.168.1.74:49145 ESTABLISHED 6072/glusterfsd tcp 0 0 192.168.1.73:59730 192.168.1.75:49145 ESTABLISHED 6072/glusterfsd tcp 0 0 192.168.1.73:59730 192.168.1.76:49150 ESTABLISHED 6072/glusterfsd tcp 0 0 127.0.0.1:24007 127.0.0.1:49145 ESTABLISHED 801/glusterd tcp 0 0 127.0.0.1:49145 127.0.0.1:24007 ESTABLISHED 6104/glusterfs tcp 0 0 192.168.1.73:24007 192.168.1.73:49146 ESTABLISHED 801/glusterd tcp 0 0 192.168.1.73:49140 192.168.1.70:49338 ESTABLISHED 6104/glusterfs tcp 0 0 192.168.1.73:49141 192.168.1.74:55571 ESTABLISHED 6104/glusterfs tcp 0 0 192.168.1.73:49145 192.168.1.73:59730 ESTABLISHED 6104/glusterfs tcp 0 0 192.168.1.73:49146 192.168.1.73:24007 ESTABLISHED 6072/glusterfsd
Cette situation est identique sur les autres machines impliquées dans ce volume; "sv4.home.dom" et "sv5.home.dom".
Mais sur les machines ne participant pas à ce volume, on trouve aussi des interconnexions; ici sur "sv1.home.dom":
tcp 0 0 127.0.0.1:24007 127.0.0.1:49146 ESTABLISHED 1215/glusterd tcp 0 0 127.0.0.1:49146 127.0.0.1:24007 ESTABLISHED 9869/glusterfs tcp 0 0 192.168.1.71:49138 192.168.1.70:49338 ESTABLISHED 9869/glusterfs tcp 0 0 192.168.1.71:49139 192.168.1.73:59730 ESTABLISHED 9869/glusterfs tcp 0 0 192.168.1.71:49140 192.168.1.74:55571 ESTABLISHED 9869/glusterfs
Il faudra en tenir compte dans le Firewall. Mais ces nouveaux ports TCP sont très aléatoires.
Statut
Les informations ci-dessus peuvent être obtenues grâce à la commande suivante pour le volume "diskgfs4":
gluster volume status diskgfs4
qui donne:
Status of volume: diskgfs4 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick sv3.home.dom:/disk1/glusterfs/brique4 59730 0 Y 6072 Brick sv4.home.dom:/disk1/glusterfs/brique4 55571 0 Y 5427 Brick sv5.home.dom:/disk1/glusterfs/brique4 49338 0 Y 4261 Self-heal Daemon on localhost N/A N/A Y 6104 Self-heal Daemon on sv1.home.dom N/A N/A Y 9869 Self-heal Daemon on sv2.home.dom N/A N/A Y 5626 Self-heal Daemon on sv4.home.dom N/A N/A Y 5459 Self-heal Daemon on sv5.home.dom N/A N/A Y 4293 Self-heal Daemon on sv6.home.dom N/A N/A Y 9536 Task Status of Volume diskgfs4 ------------------------------------------------------------------------------ There are no active volume tasks
D'autres informations peuvent être obtenues:
gluster volume info diskgfs4
qui donne:
Volume Name: diskgfs4 Type: Distributed-Replicate Volume ID: 4803549d-9008-4c3f-80a6-35aa45ff07be Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: sv3.home.dom:/disk1/glusterfs/brique4 Brick2: sv4.home.dom:/disk1/glusterfs/brique4 Brick3: sv5.home.dom:/disk1/glusterfs/brique4 Options Reconfigured: cluster.granular-entry-heal: on storage.fips-mode-rchecksum: on transport.address-family: inet nfs.disable: on performance.client-io-threads: off
On y remarque le type et le nombre de briques. Le type est combiné Distribué et Répliqué mais la partie Distribuée est simple ("1") donc non utilisée.
Modifications
Ces configurations sont dynamiquement modifiables grâce à un ensemble d'autres commandes. Il est facilement possible d'agrandir un volume; on agrandit ainsi l'espace disque global. Dans le cas d'un rétrécissement ou d'une réparation, il faut prendre des précautions pour ne pas perdre des données. Nous n'allons pas aborder ce dernier point.
Extension
Supposons que l'on désire ajouter au volume "diskgfs3" un "replica" en l'étendant sur la machine "sv3.home.dom", nous exécutons la commande suivante:
gluster volume add-brick diskgfs3 replica 3 sv3.home.dom:/disk1/glusterfs/brique3
On remarque la modification du nombre de "replica" qui de 2 passe à 3.
Maintenant voyons le statut:
gluster volume status diskgfs3
qui donne:
Status of volume: diskgfs3 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick sv1.home.dom:/disk1/glusterfs/brique3 60029 0 Y 2134 Brick sv2.home.dom:/disk1/glusterfs/brique3 56421 0 Y 11319 Brick sv3.home.dom:/disk1/glusterfs/brique3 49403 0 Y 12480 Self-heal Daemon on localhost N/A N/A Y 2614 Self-heal Daemon on sv4.home.dom N/A N/A Y 11215 Self-heal Daemon on sv2.home.dom N/A N/A Y 11463 Self-heal Daemon on sv5.home.dom N/A N/A Y 12078 Self-heal Daemon on sv3.home.dom N/A N/A Y 12512 Self-heal Daemon on sv6.home.dom N/A N/A Y 3880 Task Status of Volume diskgfs3 ------------------------------------------------------------------------------ There are no active volume tasks
Et:
gluster volume info diskgfs3
qui donne:
Volume Name: diskgfs3 Type: Distributed-Replicate Volume ID: 5f91ce00-14f4-43a7-89bc-d25c6e7896d2 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: sv1.home.dom:/disk1/glusterfs/brique3 Brick2: sv2.home.dom:/disk1/glusterfs/brique3 Brick3: sv3.home.dom:/disk1/glusterfs/brique3 Options Reconfigured: cluster.granular-entry-heal: on storage.fips-mode-rchecksum: on transport.address-family: inet nfs.disable: on performance.client-io-threads: off
Notons qu'ici, il n'est pas nécessaire d'utiliser le re-balancement qui est réservée à la distribution car elle est unique. La réplication sur la nouvelle brique se fait automatiquement.
→ retour au menu de Glusterfs - Gestion des serveurs