LINUX:Pacemaker - Serveurs en Failover
→ retour au menu de la Haute disponibilité
But
Autre application, nous allons mettre deux serveurs en Failover. Nous utiliserons l'approche utilisée par les routers mis en Failover couplée à l'utilisation de Drbd.
Principe
On dispose de deux ordinateurs Linux configurés en mode serveur. On va utiliser le logiciel Pacemaker qui les regroupent en cluster. Il sera utilisé en Failover. L'un des serveurs concentrera les ressources configurées dans Pacemaker tandis que l'autre sera en attente. Quand le premier serveur sera indisponible, par exemple suite à un problème matériel ou plus simplement lors d'une mise à jour de version, le second reprendra la tâche de serveur en récupérant les ressources de Pacemaker.
La première ressource consiste à créer une adresse IP virtuelle sur l'interface réseau "eth1" accessible par les clients; les autres "eth2" seront réservés à la synchronisation des données effectuée par la seconde ressource Drbd. L'adresse IP virtuelle sera le point d'accès pour les clients voulant utiliser les ressources du serveur. Les adresses IP réelles ne seront utilisées que pour une administration locale, par exemple, pour mettre à jour l'OS.
Le schéma suivant visualise la situation stable complètement opérationnelle. Dans ce cas, au contraire du cas des deux routeurs, aucun serveur n'a la préférence; quand le serveur qui a la main, s'arrête, le second reprend cette charge et la garde quand la situation redevient normale. Le tracé en vert visualise de trafic et l'adresse IP en rouge est virtuelle; elle n'est pas liée à un serveur mais va devoir passer de gauche à droite et inversement en fonction des besoins.
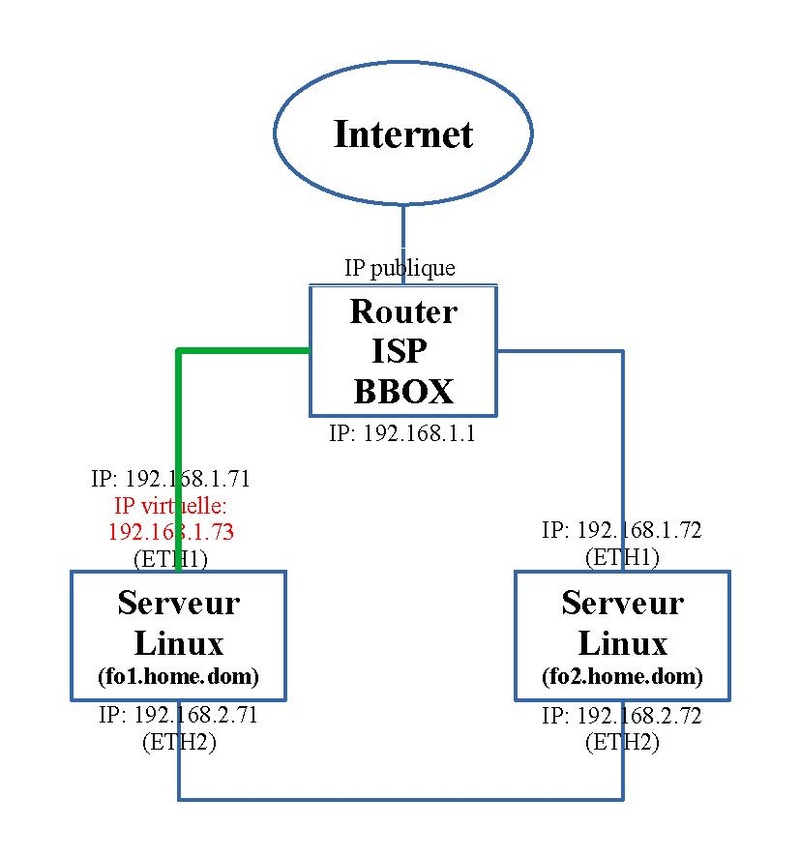
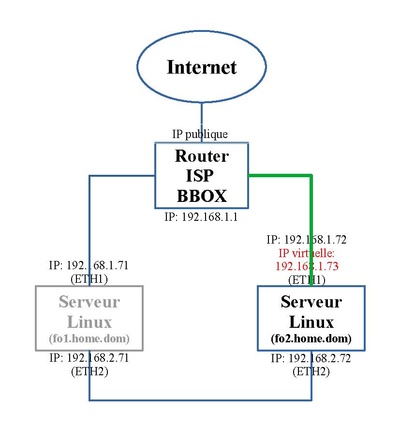
Dans le cas où le serveur de gauche tombe en panne (grisé), celui de droite prend la relève. L' adresse IP virtuelle migre sur l'autre serveur "fo2.home.dom" et la ressource Drbd de ce second serveur passe en mode Actif ("Primary").
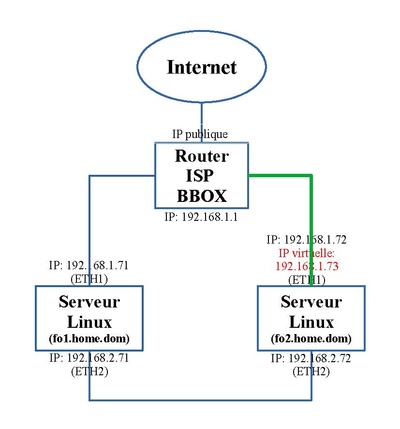
Et en situation redevenue normale.
Pour plus grande facilité de présentation, nous allons séparer la partie de d'adresse IP virtuelle, de mise en oeuvre de Drbd et de montage du disque partagé, de la partie reprenant les ressources de services propres à un serveur. Pour cette seconde partie, nous prendrons l'exemple de services Web (Apache et Php), de service de base de données (Mariadb) utilisé par nombre d'applications Web tel WordPress et enfin de services de messagerie (Postfix et Dovecot). Le tout sera en mode sécurisé incontournable actuellement grâce à l'utilisation de certificats.
Grâce à Drbd, nous disposerons d'un espace disque partagé nommé ici "/data". C'est sur cet espace que les données utilisées par ces services seront placées.
Prérequis
Configurations de base
En premier, la Configuration de base de Pacemaker doit être effectuée. Elle complétée par la mise en place de Drbd vue dans l'article précédent. Quelques uns de ces prérequis seront adaptés en cours de route.
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.71 fo1.home.dom 192.168.1.72 fo2.home.dom 192.168.1.73 cluster.home.dom 192.168.2.71 fd1.data.dom 192.168.2.72 fd2.data.dom # serveur mail 192.168.1.110 servermail.home.dom home.dom
L'adresse IP virtuelle "192.168.1.73" et le nom de machine associé "cluster.home.dom" sont cruciales pour la suite. En effet c'est par ce nom que les clients accèderont aux services du serveur actif.
Bug
Au cours de notre mise en place, nous avons été confrontés à un message d'erreur lors de la création de la ressource Drbd sous Pacemaker que ce soit par la commande "pcs" ou par l'interface Web. Ce problème était bloquant.
Voici le message d'erreur:
Error: Validation result from agent (use --force to override): ocf-exit-reason:meta parameter misconfigured, expected clone-max -le 2, but found unset. Error: Errors have occurred, therefore pcs is unable to continue
Nous utilisons la version "9.23.0-1" de Drbd sous Fedora 37.
En traçant le problème, il est apparu qu'une constante n'était pas initialisée pour effectuer correctement le test.
Dans le fichier "drbd" situé dans le répertoire "/usr/lib/ocf/resource.d/linbit" a cette tâche de création et d'utilisation de cette ressource sous Pacemaker.
Aux environs de la ligne 185 de ce fichier, nous avons ces lignes:
: ${OCF_RESKEY_CRM_meta_clone_node_max=1}
: ${OCF_RESKEY_CRM_meta_master_max=1}
: ${OCF_RESKEY_CRM_meta_master_node_max=1}
Il faut ajouter à ce bloc, la ligne:
: ${OCF_RESKEY_CRM_meta_clone_max=2}
Dès la ligne ajoutée, la création de la ressource Drbd ne pose plus de problème. Cette ligne n'a pas d'impact par la suite si elle n'est pas présente; elle n'intervient que lors de la phase de vérification des paramètres de Drbd avant son implémentation.
Configuration de la première partie
Dans cette partie, on se concentre sur l'activation de Drbd, de son espace disque partage et de l'adresse IP virtuelle.
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterDrbd ocf:linbit:drbd drbd_resource=drbddata \ op start interval=0s timeout=240s \ op stop interval=0s timeout=100s \ op monitor interval=29s role=Promoted \ op monitor interval=31s role=Unpromoted \ clone promotable=true promoted-max=1 promoted-node-max=1 clone-max=2 clone-node-max=1 notify=true pcs resource create ClusterFs ocf:heartbeat:Filesystem device="/dev/drbd1" directory="/data" fstype="xfs" pcs constraint colocation add ClusterFs with Promoted ClusterDrbd-clone score=INFINITY pcs constraint order promote ClusterDrbd-clone then start ClusterFs pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.1.73 nic=eth1 cidr_netmask=24 iflabel=ethcl1 lvs_support=true op monitor interval=30s pcs constraint colocation add ClusterIP with ClusterFs score=INFINITY pcs constraint order ClusterFs then start ClusterIP
Ces commandes ne sont à exécuter qu'à partir d'une seule machine du cluster.
Ajout de la ressource de Drbd
Les lignes suivantes:
pcs resource create ClusterDrbd ocf:linbit:drbd drbd_resource=drbddata \ op start interval=0s timeout=240s \ op stop interval=0s timeout=100s \ op monitor interval=29s role=Promoted \ op monitor interval=31s role=Unpromoted \ clone promotable=true promoted-max=1 promoted-node-max=1 clone-max=2 clone-node-max=1 notify=true
va créer une ressource, nommée "ClusterDrbd" qui va activer Drbd en mode "Actif/Passif" ("Primary/Secondery") grâce à la fonction "ocf:linbit:drbd" sur base de la ressource Drbd "drbddata". Cette ressource sera présente sur les deux machines ("clone" et "clone-max=2"). Une seule machine est "Active" ("promoted-node-max=1"). Notons que la syntaxe a évolué par rapport au passé; avant on parlait de "Master/Slave", maintenant "Promoted/Unpromoted". Ces changements de syntaxe selon les versions se rencontre un peu partout d'où la nécessité de revalider celle-ci minutieusement avant tout changement de version spécialement lors de changement de version de l'OS qui intervient tous les 6 mois dans le cas de Fedora.
Ajout de la ressource qui monte l'espace disque partagé
La ligne suivante:
pcs resource create ClusterFs ocf:heartbeat:Filesystem device="/dev/drbd1" directory="/data" fstype="xfs"
va créer la ressource disque, nommée "ClusterFs" qui va monter le device "/dev/drbd1", initiée par la ressource "drbddata", sur le répertoire "/data" en utilisant le format "xfs".
Ajout de la ressource de l'adresse IP virtuelle
La ligne suivante:
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.1.73 nic=eth1 cidr_netmask=24 iflabel=ethcl1 lvs_support=true op monitor interval=30s
va créer une ressource, nommées "ClusterIP" qui va activer l'adresse virtuelle "192.168.1.73/24" grâce à la fonction "ocf:heartbeat:IPaddr2". Elle sera placée sur l'interface réseau "eth1". Le nom virtuel sera aussi donné: "ethcl1".
Contraintes
Les contraintes d'ordre de démarrage sont connues; elles ont déjà été rencontrées dans les articles précédents. Il tombe sous le sens que la ressource "drbddata" active doit être effective avant de pouvoir monter cet espace partagé.
Les deux ressources "ClusterFs" et "ClusterIP" doivent se situer sur la même machine ("INFINITY") que la ressource Drbd (ClusterDrbd") qui est active ("Promoted"), parmi les deux ("clone"), d'où la syntaxe "Promoted ClusterDrbd-clone".
Statut de la première partie
Après cette opération, l'état du cluster peut être visualisé par la commande:
crm_mon -1
qui donne:
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-02-14 12:42:34 +01:00)
Cluster Summary:
* Stack: corosync
* Current DC: fo1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition with quorum
* Last updated: Tue Feb 14 12:42:34 2023
* Last change: Tue Feb 14 12:42:17 2023 by root via cibadmin on fo1.home.dom
* 2 nodes configured
* 4 resource instances configured
Node List:
* Online: [ fo1.home.dom fo2.home.dom ]
Active Resources:
* Clone Set: ClusterDrbd-clone [ClusterDrbd] (promotable):
* Masters: [ fo2.home.dom ]
* Slaves: [ fo1.home.dom ]
* ClusterFs (ocf::heartbeat:Filesystem): Started fo2.home.dom
* ClusterIP (ocf::heartbeat:IPaddr2): Started fo2.home.dom
On remarque que dans ce cas, c'est la machine "fo2.home.dom" qui a la main; c'est à partir de cette machine que l'on peut copier des fichiers dans le répertoire "/data". Ne pas le faire sur l'autre machine sinon ce répertoire ne pourra plus être monté.
Voyons l'état de Drbd sur la machine "fo2.home.dom":
cat /proc/drbd
qui affiche:
version: 8.4.11 (api:1/proto:86-101)
srcversion: 086EBDAD8BB6D6FF00986AA
1: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:2748 nr:0 dw:2220 dr:5018 al:6 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
La commande sur la machine "fo2.home.dom":
df -h
permet de repérer que le répertoire "/data" est monté:
Sys. de fichiers Taille Utilisé Dispo Uti% Monté sur devtmpfs 4,0M 0 4,0M 0% /dev tmpfs 1,9G 33M 1,9G 2% /dev/shm tmpfs 769M 1,1M 768M 1% /run /dev/mapper/fo2_lv1-root 15G 3,8G 12G 26% / tmpfs 1,9G 0 1,9G 0% /tmp /dev/sda1 1014M 329M 686M 33% /boot /dev/mapper/fo2_lv1-var 9,8G 1,1G 8,8G 11% /var /dev/drbd1 149G 1,2G 148G 1% /data tmpfs 385M 16K 385M 1% /run/user/0
Voici la situation de l'adressage réseau sur la machine "fo2.home.dom", qui a les ressources, avec la commande:
ifconfig
qui donne:
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.72 netmask 255.255.255.0 broadcast 192.168.1.255
ether 00:1b:21:3b:b0:77 txqueuelen 1000 (Ethernet)
RX packets 170080 bytes 147735272 (140.8 MiB)
RX errors 0 dropped 7 overruns 0 frame 0
TX packets 102619 bytes 12967633 (12.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.2.72 netmask 255.255.255.0 broadcast 192.168.2.255
ether 00:1c:c0:2a:c4:25 txqueuelen 1000 (Ethernet)
RX packets 2357 bytes 183467 (179.1 KiB)
RX errors 0 dropped 1675 overruns 0 frame 0
TX packets 2931 bytes 3036681 (2.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
device interrupt 20 memory 0xe0380000-e03a0000
eth1:ethcl1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.73 netmask 255.255.255.0 broadcast 192.168.1.255
ether 00:1b:21:3b:b0:77 txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Boucle locale)
RX packets 265 bytes 84878 (82.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 265 bytes 84878 (82.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Paramétrage des services en Failover
Maintenant que le nécessaire est en place, nous allons y placer quelques éléments pratiques: quelques services classiques. Mais avant d'aborder la suite de la configuration de Pacemaker, il nous faut les paramétrer un minimum afin de tester cet ensemble. Pour ne pas alourdir cet article, nous les avons détaillés à part.
Configuration de la seconde partie
Maintenant que les services sont configurés, on peut les intégrer au cluster à l'aide de Pacemaker.
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterHttp systemd:httpd op monitor interval=30s pcs constraint colocation add ClusterHttp with ClusterIP score=INFINITY pcs constraint order ClusterIP then start ClusterHttp pcs resource create ClusterPhp systemd:php-fpm op monitor interval=30s pcs constraint colocation add ClusterPhp with ClusterHttp score=INFINITY pcs constraint order ClusterHttp then start ClusterPhp pcs resource create ClusterMariadb systemd:mariadb op monitor interval=30s pcs constraint colocation add ClusterMariadb with ClusterPhp score=INFINITY pcs constraint order ClusterPhp then start ClusterMariadb pcs resource create ClusterPostfix systemd:postfix op monitor interval=30s pcs constraint colocation add ClusterPostfix with ClusterMariadb score=INFINITY pcs constraint order ClusterMariadb then start ClusterPostfix pcs resource create ClusterPostfixBase systemd:postfix-base op monitor interval=30s pcs constraint colocation add ClusterPostfixBase with ClusterPostfix score=-INFINITY pcs constraint order ClusterPostfix then start ClusterPostfixBase pcs resource create ClusterDovecot systemd:dovecot op monitor interval=30s pcs constraint colocation add ClusterDovecot with ClusterPostfix score=INFINITY pcs constraint order ClusterPostfix then start ClusterDovecot pcs resource create ClusterMailTo ocf:heartbeat:MailTo email=root subject="FailOver_Home" op monitor interval=30s pcs constraint colocation add ClusterMailTo with ClusterDovecot score=INFINITY pcs constraint order ClusterDovecot then start ClusterMailTo
Ajouts des ressources
La création de ces ressources des différents services sont sur le même gabari; on utilise la fonction Systemd du type "systemd:<service>". (excepté la ressource classique "ClusterMailTo" déjà vue)
Localisation des ressources
Tous les services sont placés sur la machine où Drbd est actif et que l'espace partagé "/data" est monté.
Un seul fait exception, la ressource "ClusterPostfixBase"; elle doit se placer sur la machine passive, celle qui est en attente où la ressource équivalente "ClusterPostfix" ne s'exécute pas. On utilise pour cette raison l'option "score=-INFINITY"; le moins "-" signifie à un endroit opposé.
Ordre de lancement des ressources
Nous avons déjà rencontré ce type de commande; chaque service est chargé chacun à la suite de l'autre après la ressource "ClusterIP".
Statut après l'activation de la seconde partie
Après cette opération, l'état du cluster peut être visualisé par la commande:
crm_mon -1
qui donne:
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-02-15 19:25:01 +01:00)
Cluster Summary:
* Stack: corosync
* Current DC: fo1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition with quorum
* Last updated: Wed Feb 15 19:25:02 2023
* Last change: Wed Feb 15 19:24:54 2023 by root via cibadmin on fo1.home.dom
* 2 nodes configured
* 11 resource instances configured
Node List:
* Online: [ fo1.home.dom fo2.home.dom ]
Active Resources:
* Clone Set: ClusterDrbd-clone [ClusterDrbd] (promotable):
* Masters: [ fo2.home.dom ]
* Slaves: [ fo1.home.dom ]
* ClusterFs (ocf::heartbeat:Filesystem): Started fo2.home.dom
* ClusterIP (ocf::heartbeat:IPaddr2): Started fo2.home.dom
* ClusterHttp (systemd:httpd): Started fo2.home.dom
* ClusterPhp (systemd:php-fpm): Started fo2.home.dom
* ClusterMariadb (systemd:mariadb): Started fo2.home.dom
* ClusterPostfix (systemd:postfix): Started fo2.home.dom
* ClusterPostfixBase (systemd:postfix-base): Starting fo1.home.dom
* ClusterDovecot (systemd:dovecot): Starting fo2.home.dom
On remarque que seule la ressource "ClusterPostfixBase" s'exécute sur l'autre machine "fo1.home.dom".
Accès pour les clients
Notons que sur les machines clients, le nom de machine "cluster.home.dom" doit être connu et lié à l'adresse IP "192.168.1.73". (serveur DNS ou fichiers "hosts" local)
Pour accéder au site Web, l'URL est:
https://cluster.home.dom
qui affichera:
Nom du serveur: fo2.home.dom
Du côté de la messagerie, Le serveur est "cluster.home.dom". Par exemple pour l'utilisateur "pdupont", l'adresse mail est "pdupont@failover.dom" et le nom de compte est "pdupont" accompagné du mot de passe Linux associé. Le reste est classique.
→ retour au menu de la Haute disponibilité