LINUX:Pacemaker - quatre serveurs WEB en Failover, Fsyncd et ISCSI
→ retour au menu de la Haute disponibilité
But
Autre configuration, nous allons configurer 4 serveurs WEB en failover. Ils seront accompagnés d'une réplication grâce au programme Fsyncd. Un accès à un espace disque distant ISCSI, propre à chaque serveur WEB sera ajouté.
Matériel et adressage IP
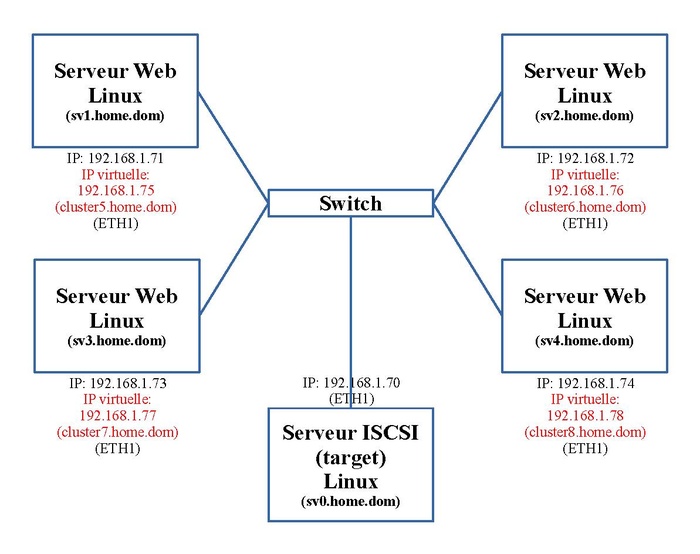
Dans notre exemple, nous utilisons quatre serveurs Web mis en cluster et un serveur ISCSI ("target") qui mettra à disposition de chaque serveur Web, un espace disque ISCSI. Le schéma ci-dessous nous montre l'adressage IP et le nom de ces machines. En outre pour mettre la fonction Failover, une adresse IP virtuelle est ajoutée à chaque serveur Web.
Principe
En mode d'utilisation complet, nous avons quatre services Web répartis sur quatre machines mises en cluster: "sv1.home.dom", "sv2.home.dom", "sv3.home.dom" et "sv4.home.dom". A chaque service Web est associé une adresse IP virtuelle propre et un nom de domaine virtuel propre ou nom de machine virtuelle. Ce nom de machine virtuelle et son adresse IP virtuelle seront repris comme "VirtualHost" dans la configuration du service Web HTTP d'Apache.
Associations:
| Description | Nom de machine virtuelle | Adresse IP virtuelle | Machine réelle préférée | Adresse IP réelle préférée |
|---|---|---|---|---|
| Service Web n° 5 | cluster5.home.dom | 192.168.1.75 | sv1.home.dom | 192.168.1.71 |
| Service Web n° 6 | cluster6.home.dom | 192.168.1.76 | sv2.home.dom | 192.168.1.72 |
| Service Web n° 7 | cluster7.home.dom | 192.168.1.77 | sv3.home.dom | 192.168.1.73 |
| Service Web n° 8 | cluster8.home.dom | 192.168.1.78 | sv4.home.dom | 192.168.1.74 |
Dans de nombreuses configurations d'un site Web, nous avons les composantes suivantes:
- le code statique du site écrit par exemple en HTML et en PHP
- une base de sonnées SQL contenant la partie dynamique de mise en page et du contenu du site
- un espace disque contenant tous les médias dynamiques téléchargés (images, film, documents PDF,...) qui viendront étoffer le site.
C'est ce que nous rencontrons dans des systèmes de gestion de contenu (CMS) tels Wordpress, Mediawiki, Drupal, Joomla, SPIP,...
Le code statique du site doit être accessible à partir de chaque machine Web. Ces fichiers ne sont généralement que peu nombreux et ne subissent que rarement de modifications.
Ces modifications n'apparaissent que lors de mises à jour ou lors d'ajout ou de suppression de "plugins".
En le gardant localement nous y gagnerons en performances.
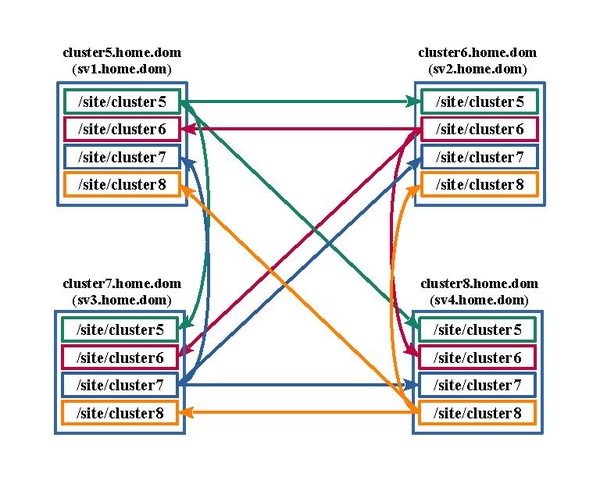
Pour cette raison, nous optons pour une réplication entre machines hébergeant les services Web, basée sur le service Rsyncd. L'espace disque utilisé localement par un service Web sera synchronisé toutes les 10 secondes avec son espace disque homologue sur les autres machines du cluster.
Associations:
| Description | Répertoire local |
|---|---|
| Service Web n° 5 | /site/cluster5 |
| Service Web n° 6 | /site/cluster6 |
| Service Web n° 7 | /site/cluster7 |
| Service Web n° 8 | /site/cluster8 |
Le schéma suivant illustre ces synchronisations.
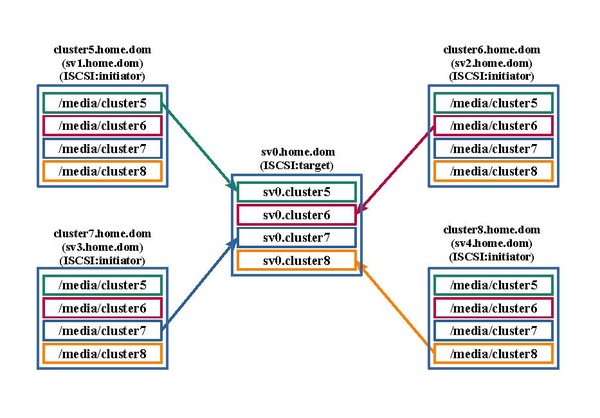
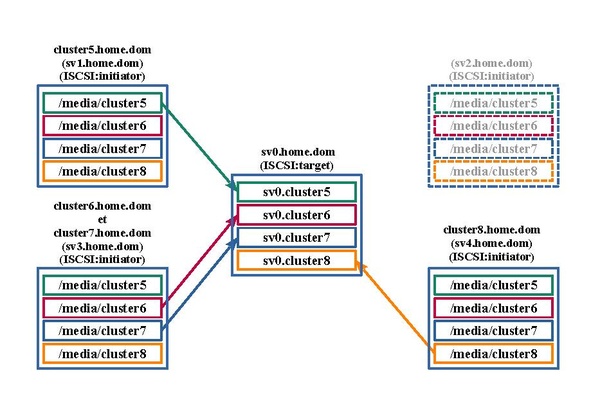
A chaque service Web sera associé un espace disque distant ISCSI mis à disposition par un serveur ISCSI Target: "sv0.home.dom".
Cet espace peut être utilisé pour l'hébergement des médias dynamiques téléchargés.
Associations:
| Description | Répertoire local | Nom Initiator ISCSI | Target ISCSI |
|---|---|---|---|
| Service Web n° 5 | /media/cluster5 | iqn.2023-03.dom.home.sv:sv.initiator05 | iqn.2023-03.dom.home.sv0:sv0.cluster5 |
| Service Web n° 6 | /media/cluster6 | iqn.2023-03.dom.home.sv:sv.initiator06 | iqn.2023-03.dom.home.sv0:sv0.cluster6 |
| Service Web n° 7 | /media/cluster7 | iqn.2023-03.dom.home.sv:sv.initiator07 | iqn.2023-03.dom.home.sv0:sv0.cluster7 |
| Service Web n° 8 | /media/cluster8 | iqn.2023-03.dom.home.sv:sv.initiator08 | iqn.2023-03.dom.home.sv0:sv0.cluster8 |
Le schéma suivant illustre ces accès.
En ce qui concerne la base de données, elle doit être hébergée sur une machine distante par exemple sur notre machine "sv0.home.dom".
Remarques:
- Pour gagner en performances, il serait préférable de placer la partie du trafic ISCSI et base de données sur un second réseau local (interfaces ETH2) comme nous le faisions pour le trafic DRBD dans un article précédent. On ne garde que l'accès des clients Web sur les interfaces réseaux ETH1.
- Pour gagner en haute disponibilité, la machine "sv0.home.dom" pourrait être mise en Failover avec une réplication disque basée sur Drbd en mode Actif/Passif comme vu précédemment (Serveurs en Failover) en l'adaptant à ISCSI.
- On pourrait ajouter le "fencing" grâce au support SBD sous ISCSI comme vu précédemment (ISCSI en Failover et SBD (fence)).
- Comme on pourrait intégrer le serveur "sv0.home.dom" dans le cluster comme vu précédemment (ISCSI en Failover).
Nous n'avons pas intégré ces facettes pour ne pas alourdir et compliquer l'exposé.
En cas de défaillance d'une machine du cluster, les différentes ressources de la machine défaillante seront transférés sur une des trois autres machines et ainsi de suite pour aboutir dans le cas extrême que toutes les ressources soient concentrées sur une seule machine.
Le schéma suivant simule l'arrêt de la machine "sv2.home.dom". Ses ressources sont transférés sur la machine "sv3.home.dom".
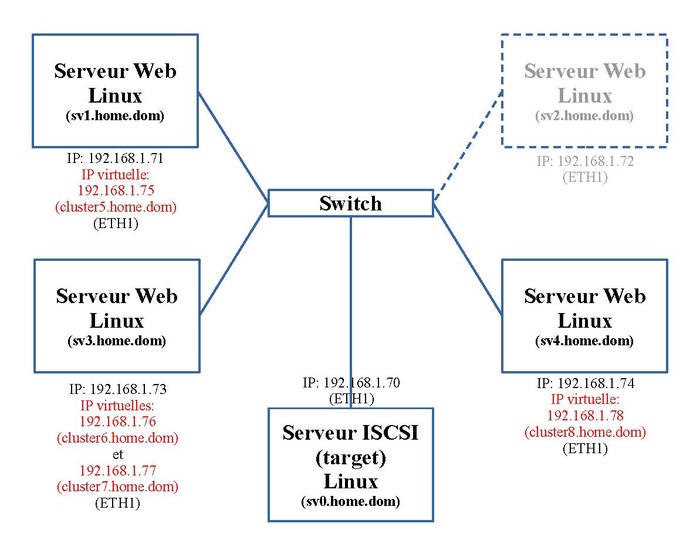
De même pour la synchronisation Rsync.
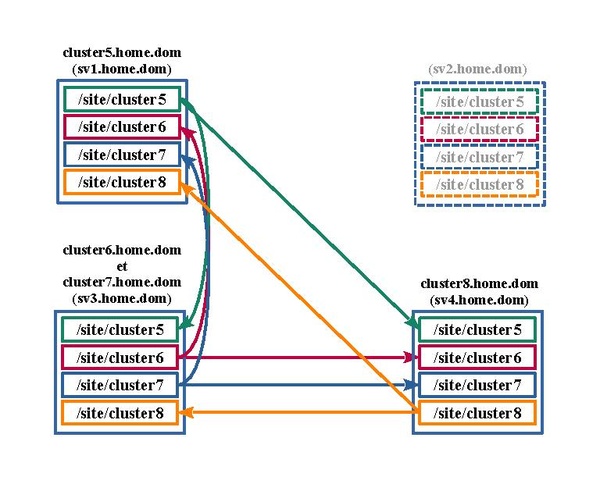
De même pour les accès ISCSI.
Prérequis
Configurations de base
En premier, les Prérequis doivent être effectués.
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.70 sv0.home.dom 192.168.1.71 sv1.home.dom 192.168.1.72 sv2.home.dom 192.168.1.73 sv3.home.dom 192.168.1.74 sv4.home.dom 192.168.1.75 cluster5.home.dom 192.168.1.76 cluster6.home.dom 192.168.1.77 cluster7.home.dom 192.168.1.78 cluster8.home.dom # serveur mail 192.168.1.110 servermail.home.dom home.dom
ISCSI
Nous nous baserons sur la configuration de l'article sur ISCSI. Nous expliciterons la configuration ci-dessous sans entrer dans les détails.
Configuration de base de Pacemaker
La Configuration de base de Pacemaker doit être effectuée avec quelques modifications car nous avons quatre machines dans le cluster au lieu de deux. Nous allons passer rapidement en revue ces opérations.
Opérations locales
Sur chaque machine:
- le mot de passe de l'utilisateur "hacluster" est à implémenter. "Chasse4321Eau" pour mémoire.
- le service "pcsd.service" est à configurer et est lancé.
Initialisation du cluster
Pour initialiser le cluster, on effectue ces opérations sur une seule machine du cluster:
pcs host auth sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom -u hacluster -p Chasse4321Eau pcs cluster setup fo_cluster \ sv1.home.dom addr=192.168.1.71 sv2.home.dom addr=192.168.1.72 sv3.home.dom addr=192.168.1.73 sv4.home.dom addr=192.168.1.74 \ transport knet ip_version=ipv4 link transport=udp mcastport=5420
Quorum
Pour la suite, nous sommes en présence d'un problème.
- Si nous ignorons la contrainte du "quorum" avec la commande:
pcs property set no-quorum-policy=ignore
quand ne subsiste qu'une machine active, les ressources "lsyncd" n'ont plus rien à synchroniser et se mettent en erreur.
- Si nous maintenons la contrainte du "quorum" avec la commande, :
pcs property set no-quorum-policy=stop
le "quorum" est de 3; c'est à dire que s'il n'y a pas au moins 3 machines actives, le système s'arrête.
- Le système idéal et minimum serait que le "quorum" soit de 2. Dans un autre article, nous avions joué sur l'option "expected_votes" dans le fichier "/etc/corosync/corosync.conf". Mais cette valeur n'est prise en compte que si elle est supérieure ou égale au nombre de machines présentes dans le cluster. Nous allons utiliser l'option "last_man_standing".
Modification de la configuration de Corosync
Pour atteindre ce quorum de deux, il faut adapter sur chaque machine du cluster, le fichier "/etc/corosync/corosync.conf". La dernière commande a créé ce fichier. Dans la section "quorum", on va ajouter l'option "last_man_standing: 1". Cette option recalcule le "quorum" en fonction du nombre de machines actives dans le cluster et non sur base du nombre total de machines configurées dans le cluster.
Ce fichier devient pour la section "quorum":
quorum {
provider: corosync_votequorum
last_man_standing: 1
}
Avec cette configuration, le "quorum" minimum sera de 2 et c'est seulement quand il ne restera qu'une machine active que le système de Failover s'arrêtera.
Voici comment cela se passera. on utilise la commande:
pcs quorum status
qui donne:
- dans le cas de quatre machines actives:
Quorum information
------------------
Date: Tue Mar 28 12:59:53 2023
Quorum provider: corosync_votequorum
Nodes: 4
Node ID: 1
Ring ID: 1.2c7
Quorate: Yes
Votequorum information
----------------------
Expected votes: 4
Highest expected: 4
Total votes: 4
Quorum: 3
Flags: Quorate LastManStanding
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 NR sv1.home.dom (local)
2 1 NR sv2.home.dom
3 1 NR sv3.home.dom
4 1 NR sv4.home.dom
- dans le cas de trois machines actives:
Quorum information
------------------
Date: Tue Mar 28 12:58:25 2023
Quorum provider: corosync_votequorum
Nodes: 3
Node ID: 1
Ring ID: 1.2c3
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate LastManStanding
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 NR sv1.home.dom (local)
2 1 NR sv2.home.dom
4 1 NR sv4.home.dom
- dans le cas de deux machines actives:
Quorum information
------------------
Date: Tue Mar 28 12:55:45 2023
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 1
Ring ID: 1.2b7
Quorate: Yes
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2
Flags: Quorate LastManStanding
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 NR sv1.home.dom (local)
3 1 NR sv3.home.dom
Lancement du cluster
Pour lancer l'ensemble, on exécute les commandes suivantes à partir d'une seule machine:
pcs cluster enable --all pcs cluster start --all
On n'oublie pas d'activer les trois services sur les quatres machines du cluster:
systemctl enable pcsd.service corosync.service pacemaker.service
Fin de la configuration
Par la même occasion exécutez la fin de la configuration de base:
pcs property set stonith-enabled=false pcs property set no-quorum-policy=stop
La dernière spécifie que si le quorum n'est pas atteint, les ressources de Pacemaker sont arrêtées.
Configuration du service WEB
Passons à la configuration du service Web sur les quatre machines du cluster.
Configuration des adresses IP virtuelle et des serveurs Web sous Pacemaker
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterIP5 ocf:heartbeat:IPaddr2 ip=192.168.1.75 nic=eth1 cidr_netmask=24 iflabel=ethcl5 lvs_support=true op monitor interval=30s pcs constraint location ClusterIP5 prefers sv1.home.dom=400 pcs constraint location ClusterIP5 prefers sv2.home.dom=100 pcs constraint location ClusterIP5 prefers sv3.home.dom=100 pcs constraint location ClusterIP5 prefers sv4.home.dom=100 pcs resource create ClusterIP6 ocf:heartbeat:IPaddr2 ip=192.168.1.76 nic=eth1 cidr_netmask=24 iflabel=ethcl6 lvs_support=true op monitor interval=30s pcs constraint location ClusterIP6 prefers sv1.home.dom=100 pcs constraint location ClusterIP6 prefers sv2.home.dom=400 pcs constraint location ClusterIP6 prefers sv3.home.dom=100 pcs constraint location ClusterIP6 prefers sv4.home.dom=100 pcs resource create ClusterIP7 ocf:heartbeat:IPaddr2 ip=192.168.1.77 nic=eth1 cidr_netmask=24 iflabel=ethcl7 lvs_support=true op monitor interval=30s pcs constraint location ClusterIP7 prefers sv1.home.dom=100 pcs constraint location ClusterIP7 prefers sv2.home.dom=100 pcs constraint location ClusterIP7 prefers sv3.home.dom=400 pcs constraint location ClusterIP7 prefers sv4.home.dom=100 pcs resource create ClusterIP8 ocf:heartbeat:IPaddr2 ip=192.168.1.78 nic=eth1 cidr_netmask=24 iflabel=ethcl8 lvs_support=true op monitor interval=30s pcs constraint location ClusterIP8 prefers sv1.home.dom=100 pcs constraint location ClusterIP8 prefers sv2.home.dom=100 pcs constraint location ClusterIP8 prefers sv3.home.dom=100 pcs constraint location ClusterIP8 prefers sv4.home.dom=400 pcs resource create ClusterHttpd systemd:httpd op monitor interval=30s clone pcs resource create ClusterPhp systemd:php-fpm op monitor interval=30s clone pcs resource create ClusterMailTo ocf:heartbeat:MailTo email=root subject="FailOver_Home" op monitor interval=30s clone
Ajout des ressources des adresses IP virtuelles
Nous créons les ressources "ClusterIP5", "ClusterIP6", "ClusterIP7" et "ClusterIP8" grâce à la fonction "ocf:heartbeat:IPaddr2".
On remarque qu'on a ajouté des contraintes de localisation par machine du cluster. Pour chacune de ces ressources, une machine différente préférentielle a été choisie. La ressource "ClusterIP5" sera activée sur la machine "sv1.home.dom" (valeur "400") et ainsi de suite. Chaque machine aura sa propre adresse IP virtuelle prédéfinie. Dans le cas d'une déficience de cette machine, cette ressource sera placée aléatoirement sur une des trois autres machines du cluster; elles ont en effet le même score préférentiel (valeur "100").
Ajout des ressources clonées
Les trois dernières lignes créent trois ressources de type clone; ces ressources se retrouveront d'office sur toutes les machines du cluster.
- La ressource "ClusterHttpd" va activer le service Apache configurée au point précédent.
- La ressource "ClusterPhp" va activer le service Php.
- La ressource "ClusterMailTo" va activer les notifications par mail.
Configuration des services Lsyncd
Passons à la configuration des services Lsyncd sur les quatre machines du cluster. Ce service est basé sur le logiciel Rsync et le logiciel Lsyncd entrera en relation avec service Rsyncd.
Configuration des services Lsyncd sous Pacemaker
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterLsyncd5 systemd:lsyncd5 op monitor interval=30s pcs constraint colocation add ClusterIP5 with ClusterLsyncd5 score=INFINITY pcs constraint order ClusterIP5 then start ClusterLsyncd5 pcs resource create ClusterLsyncd6 systemd:lsyncd6 op monitor interval=30s pcs constraint colocation add ClusterIP6 with ClusterLsyncd6 score=INFINITY pcs constraint order ClusterIP6 then start ClusterLsyncd6 pcs resource create ClusterLsyncd7 systemd:lsyncd7 op monitor interval=30s pcs constraint colocation add ClusterIP7 with ClusterLsyncd7 score=INFINITY pcs constraint order ClusterIP7 then start ClusterLsyncd7 pcs resource create ClusterLsyncd8 systemd:lsyncd8 op monitor interval=30s pcs constraint colocation add ClusterIP8 with ClusterLsyncd8 score=INFINITY pcs constraint order ClusterIP8 then start ClusterLsyncd8
Ajout des ressources des services Lsyncd
Nous créons les ressources "ClusterLsyncd5", "ClusterLsyncd6", "ClusterLsyncd7" et "ClusterLsyncd8" sur base des services créés au point précédent. Chacune de ces ressources est liée respectivement à leur homologue "ClusterIP5", "ClusterIP6", "ClusterIP7" et "ClusterIP8". Elles suivent une contrainte de colocation. Elles sont lancées après leur équivalent de la ressource d'adressage IP virtuelle.
Configuration d'Iscsi - Target et initiator
Passons à la configuration d'ISCSI. La partie ISCSI Target sera concentrée sur la machine "sv0.home.dom" et les quatre machines du cluster utiliseront ce service en tant qu'ISCSI Initiator.
Configuration d'ISCSI sous Pacemaker
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterIscsi5 ocf:heartbeat:iscsi portal=192.168.1.70:3260 target=iqn.2023-03.dom.home.sv0:sv0.cluster5 op monitor pcs constraint colocation add ClusterIscsi5 with ClusterLsyncd5 score=INFINITY pcs constraint order ClusterLsyncd5 then start ClusterIscsi5 pcs resource create ClusterIscsi6 ocf:heartbeat:iscsi portal=192.168.1.70:3260 target=iqn.2023-03.dom.home.sv0:sv0.cluster6 op monitor pcs constraint colocation add ClusterIscsi6 with ClusterLsyncd6 score=INFINITY pcs constraint order ClusterLsyncd6 then start ClusterIscsi6 pcs resource create ClusterIscsi7 ocf:heartbeat:iscsi portal=192.168.1.70:3260 target=iqn.2023-03.dom.home.sv0:sv0.cluster7 op monitor pcs constraint colocation add ClusterIscsi7 with ClusterLsyncd7 score=INFINITY pcs constraint order ClusterLsyncd7 then start ClusterIscsi7 pcs resource create ClusterIscsi8 ocf:heartbeat:iscsi portal=192.168.1.70:3260 target=iqn.2023-03.dom.home.sv0:sv0.cluster8 op monitor pcs constraint colocation add ClusterIscsi8 with ClusterLsyncd8 score=INFINITY pcs constraint order ClusterLsyncd8 then start ClusterIscsi8
Ajout des ressources ISCSI
Nous créons les ressources "ClusterIscsi5", "ClusterIscsi6", "ClusterIscsi7" et "ClusterIscsi8" grâce à la fonction "ocf:heartbeat:iscsi". Chacune de ces ressources est liée respectivement à leur homologue "ClusterLsyncd5", "ClusterLsyncd6", "ClusterLsyncd7" et "ClusterLsyncd8". Elles suivent une contrainte de colocation. Elles sont lancées après leur équivalent de la ressource du service Lsyncd. Nous remarquons qu'on utilise les noms de target et du portal vu au point précédent.
Configuration du montage des ressources disques ISCSI sous Pacemaker
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterFsData5 ocf:heartbeat:Filesystem \ device="/dev/disk/by-uuid/5506f7a0-3fee-48ad-a753-e4050f61b654" \ directory="/media/cluster5" fstype="xfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop pcs constraint colocation add ClusterFsData5 with ClusterIscsi5 score=INFINITY pcs constraint order ClusterIscsi5 then start ClusterFsData5 pcs resource create ClusterFsData6 ocf:heartbeat:Filesystem \ device="/dev/disk/by-uuid/c5c6a292-00e2-4f5b-8157-dcfd34c07bd9" \ directory="/media/cluster6" fstype="xfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop pcs constraint colocation add ClusterFsData6 with ClusterIscsi6 score=INFINITY pcs constraint order ClusterIscsi6 then start ClusterFsData6 pcs resource create ClusterFsData7 ocf:heartbeat:Filesystem \ device="/dev/disk/by-uuid/d4e00f02-a83f-4379-accf-60357830147a" \ directory="/media/cluster7" fstype="xfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop pcs constraint colocation add ClusterFsData7 with ClusterIscsi7 score=INFINITY pcs constraint order ClusterIscsi7 then start ClusterFsData7 pcs resource create ClusterFsData8 ocf:heartbeat:Filesystem \ device="/dev/disk/by-uuid/8fbb22bd-8624-4ff0-91a1-ac1f6bb051e4" \ directory="/media/cluster8" fstype="xfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop pcs constraint colocation add ClusterFsData8 with ClusterIscsi8 score=INFINITY pcs constraint order ClusterIscsi8 then start ClusterFsData8
Ajout des ressources de montage des disques ISCSI
Nous créons les ressources "ClusterFsData5", "ClusterFsData6", "ClusterFsData7" et "ClusterFsData8" grâce à la fonction "ocf:heartbeat:Filesystem". Chacune de ces ressources est liée respectivement à leur homologue "ClusterIscsi5", "ClusterIscsi6", "ClusterIscsi7" et "ClusterIscsi8". Elles suivent une contrainte de colocation. Elles sont lancées après leur équivalent de la ressource ISCSI. Nous retrouvons le nom du device que nous avions listés lors du point précédent.
Synthèse concernant la colocation
Des groupes de ressources se retrouveront toujours ensemble sur une même machine du cluster:
- Les ressources "ClusterIP5", "ClusterLsyncd5", "ClusterIscsi5" et "ClusterFsData5" restent ensemble.
- Les ressources "ClusterIP6", "ClusterLsyncd6", "ClusterIscsi6" et "ClusterFsData6" restent ensemble.
- Les ressources "ClusterIP7", "ClusterLsyncd7", "ClusterIscsi7" et "ClusterFsData7" restent ensemble.
- Les ressources "ClusterIP8", "ClusterLsyncd8", "ClusterIscsi8" et "ClusterFsData8" restent ensemble.
Statut
Après cette opération, l'état du cluster peut être visualisé par la commande:
crm_mon -1
qui donne dans le cas des cinq machines actives. En effet, il faut que la machine serveur ISCSI Target "sv0.home.dom":
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-03-29 13:10:18 +02:00)
Cluster Summary:
* Stack: corosync
* Current DC: sv1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition with quorum
* Last updated: Wed Mar 29 13:10:19 2023
* Last change: Tue Mar 28 12:59:32 2023 by root via cibadmin on sv1.home.dom
* 4 nodes configured
* 28 resource instances configured
Node List:
* Online: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
Active Resources:
* ClusterIP5 (ocf::heartbeat:IPaddr2): Started sv1.home.dom
* ClusterIP6 (ocf::heartbeat:IPaddr2): Started sv2.home.dom
* ClusterIP7 (ocf::heartbeat:IPaddr2): Started sv3.home.dom
* ClusterIP8 (ocf::heartbeat:IPaddr2): Started sv4.home.dom
* Clone Set: ClusterHttpd-clone [ClusterHttpd]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Clone Set: ClusterPhp-clone [ClusterPhp]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Clone Set: ClusterMailTo-clone [ClusterMailTo]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* ClusterLsyncd5 (systemd:lsyncd5): Started sv1.home.dom
* ClusterLsyncd6 (systemd:lsyncd6): Started sv2.home.dom
* ClusterLsyncd7 (systemd:lsyncd7): Started sv3.home.dom
* ClusterLsyncd8 (systemd:lsyncd8): Started sv4.home.dom
* ClusterIscsi5 (ocf::heartbeat:iscsi): Started sv1.home.dom
* ClusterIscsi6 (ocf::heartbeat:iscsi): Started sv2.home.dom
* ClusterIscsi7 (ocf::heartbeat:iscsi): Started sv3.home.dom
* ClusterIscsi8 (ocf::heartbeat:iscsi): Started sv4.home.dom
* ClusterFsData5 (ocf::heartbeat:Filesystem): Started sv1.home.dom
* ClusterFsData6 (ocf::heartbeat:Filesystem): Started sv2.home.dom
* ClusterFsData7 (ocf::heartbeat:Filesystem): Started sv3.home.dom
* ClusterFsData8 (ocf::heartbeat:Filesystem): Started sv4.home.dom
Et dans le cas où la machine "sv2.home.dom" est arrêtée:
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-03-24 10:34:40 +01:00)
Cluster Summary:
* Stack: corosync
* Current DC: sv1.home.dom (version 2.1.5-3.fc37-a3f44794f94) - partition with quorum
* Last updated: Fri Mar 24 10:34:40 2023
* Last change: Thu Mar 23 13:11:24 2023 by root via cibadmin on sv1.home.dom
* 4 nodes configured
* 28 resource instances configured
Node List:
* Online: [ sv1.home.dom sv3.home.dom sv4.home.dom ]
* OFFLINE: [ sv2.home.dom ]
Active Resources:
* ClusterIP5 (ocf::heartbeat:IPaddr2): Started sv1.home.dom
* ClusterIP6 (ocf::heartbeat:IPaddr2): Started sv3.home.dom
* ClusterIP7 (ocf::heartbeat:IPaddr2): Started sv3.home.dom
* ClusterIP8 (ocf::heartbeat:IPaddr2): Started sv4.home.dom
* Clone Set: ClusterHttpd-clone [ClusterHttpd]:
* Started: [ sv1.home.dom sv3.home.dom sv4.home.dom ]
* Clone Set: ClusterPhp-clone [ClusterPhp]:
* Started: [ sv1.home.dom sv3.home.dom sv4.home.dom ]
* Clone Set: ClusterMailTo-clone [ClusterMailTo]:
* Started: [ sv1.home.dom sv3.home.dom sv4.home.dom ]
* ClusterLsyncd5 (systemd:lsyncd5): Started sv1.home.dom
* ClusterLsyncd6 (systemd:lsyncd6): Started sv3.home.dom
* ClusterLsyncd7 (systemd:lsyncd7): Started sv3.home.dom
* ClusterLsyncd8 (systemd:lsyncd8): Started sv4.home.dom
* ClusterIscsi5 (ocf::heartbeat:iscsi): Started sv1.home.dom
* ClusterIscsi6 (ocf::heartbeat:iscsi): Started sv3.home.dom
* ClusterIscsi7 (ocf::heartbeat:iscsi): Started sv3.home.dom
* ClusterIscsi8 (ocf::heartbeat:iscsi): Started sv4.home.dom
* ClusterFsData5 (ocf::heartbeat:Filesystem): Started sv1.home.dom
* ClusterFsData6 (ocf::heartbeat:Filesystem): Started sv3.home.dom
* ClusterFsData7 (ocf::heartbeat:Filesystem): Started sv3.home.dom
* ClusterFsData8 (ocf::heartbeat:Filesystem): Started sv4.home.dom
→ retour au menu de la Haute disponibilité