LINUX:Pacemaker - quatre serveurs WEB en Loadbalancing, Galera et GlusterFs
→ retour au menu de la Haute disponibilité
But
Cette configuration rassemble les fonctionnalités de l'article précédent, Cinq serveurs WEB en Failover, Galera et GlusterFs auquel on applique le canevas du schéma présenté dans l'article sur les Serveurs en Loadbalancing (masq). A l'approche Drbd on substitue GlusterFs. La fonction de Loadbalancing est assurée par le paquet Ldirectord en mode Mask.
Matériel et adressage IP
Dans notre exemple, nous utilisons quatre serveurs Web mis en cluster sous le réseau "192.168.2.0/24". Pour améliorer les performances et de sécurité, le trafic généré par la réplication des espaces disques se fera au travers d'un troisième réseau ("192.168.3.0/24"), chaque machine est pour cette raison équipée d'une seconde carte réseau. La fonctionnalité de Loadbalancing est assurée par un router qui fait la répartition des tâches et la liaison avec la Lan d'entrée.
Le schéma ci-dessous nous montre l'adressage IP et le nom de ces machines.
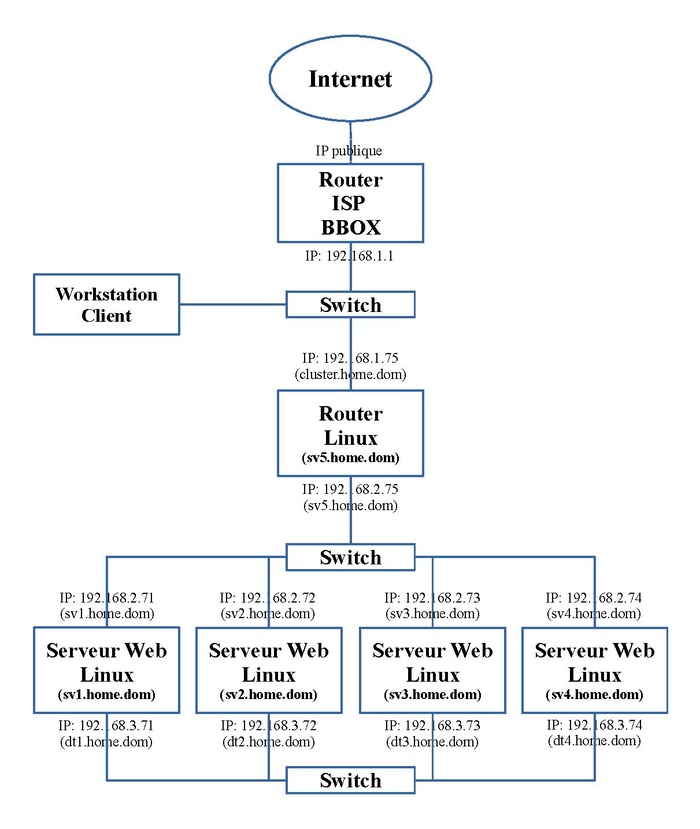
Principe
Nous avons quatre serveurs Web gérants le même site. La charge Web sera répartie équitablement entre ces quatre serveurs Web. Cette tâche est assurée par le paquet Ldirectord en mode "Mask". Il se place sur le router "sv5.home.dom". Ce site utilisera le cryptage SSL sous le nom de "cluster.home.dom". Pour cette raison, l'interface réseau utilisé par les utilisateurs sera accessible sous le nom "cluster.home.dom" du réseau "192.168.1.0/24". La configuration du router "192.168.1.75" peut être trouvée dans l'article sur le Routage statique. Dans cadre d'un réseau à domicile, vous aurez des problème d'appliquer un routage statique; l'article suivant vous aidera à le résoudre via le Natting.
Les fichiers utilisés pour ce site sont placés dans un espace disque commun aux quatre serveurs. Pour cette tâche, nous utilisons un volume GlusterFs en réplication. La réplication se passe au travers du réseau "192.168.3.0/24".
Ce site utilise une base de données. Chacun de ces quatre serveurs comporte une base de données; elles sont identiques. Cette réplication se fait grâce au gestionnaire de base de données Mariadb-Galera au travers du réseau "192.168.2.0/24". Comme nous avons un nombre paire de serveurs de base de données, nous devons utiliser le service Garb; il se placera sur la machine "sv5.home.dom".
Toute cette configuration sera supervisée par le logiciel Pacemaker. Il assurera que l'ensemble fonctionne et dans le cas extrême, l'ensemble des applications concernées s'arrêtera.
Pour cette mise en place, deux grandes parties sont à considérer:
- la configuration des quatre serveurs qui vont travailler de concert.
- la configuration du router qui aura la tâche de rediriger et répartir les requêtes des clients.
Avant de passer à Pacemaker.
Prérequis
Configurations de base
En premier, les Prérequis doivent être effectués.
Fichier "hosts"
Sur chaque machine du cluster, on ajoute un nom aux différentes adresses réseaux. On le fait en local dans le fichier "/etc/hosts" suivant le schéma ci-dessus. Son contenu devient:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.75 cluster.home.dom cluster 192.168.2.75 sv5.home.dom sv5 192.168.2.71 sv1.home.dom sv1 192.168.2.72 sv2.home.dom sv2 192.168.2.73 sv3.home.dom sv3 192.168.2.74 sv4.home.dom sv4 192.168.3.71 dt1.home.dom dt1 192.168.3.72 dt2.home.dom dt2 192.168.3.73 dt3.home.dom dt3 192.168.3.74 dt4.home.dom dt4 # serveur mail 192.168.1.110 servermail.home.dom home.dom
Configuration des services sur les serveurs Web
Nous avons à configurer les différents services nécessaires qui vont être utilisés par Pacemaker. Ces configurations sont à faire sur les quatre serveurs Web: "192.168.2.71", "192.168.2.72", "192.168.2.73" et "192.168.2.74".
Service GlusterFs
Sur chaque machine, il faut configurer le serveur Gluster. La configuration se base sur celle présentée dans l'article sur Glusterfs. Toute la configuration centralisée se fera à partir de la machine "sv1.home.dom".
Le volume sera placé sur un partition d'un disque distinct que nous avons monté sur le répertoire "/disk1".
Démarrage
Sur chaque machine, on lance le service "glusterd.service":
systemctl start glusterd.service
Constitution du "Pool"
On constitue le "Pool" de serveurs qui va utiliser le réseau "192.168.3.0/24". Voici la suite des commandes:
gluster peer probe dt2.home.dom gluster peer probe dt3.home.dom gluster peer probe dt4.home.dom
Constitution du volume en réplication
On crée ensuite le volume en réplication "diskgfs1" sur les quatre machines:
gluster volume create diskgfs1 replica 4 transport tcp dt1.home.dom:/disk1/glusterfs/brique1 dt2.home.dom:/disk1/glusterfs/brique1 \
dt3.home.dom:/disk1/glusterfs/brique1 dt4.home.dom:/disk1/glusterfs/brique1
gluster volume start diskgfs1
Services HTTPD et PHP
Les fichiers des sites se trouvent sous le répertoire "/web". Cet espace sera monté sur le volume GlusterFs configuré ci-dessus.
mkdir /data mount -t glusterfs localhost:/diskgfs1 /data
La configuration est similaire à celle présentée dans l'article sur le Paramétrage des services en Failover. La mise en place des certificats est nécessaire. Celle concernant la messagerie n'est pas reprise dans ce cas-ci même si elle pourrait y être ajoutée facilement. La configuration de Mariadb sera abordée ci-dessous. Nous plaçons les fichiers du site sous le répertoire "/data/web".
On ajoute un fichier "/data/web/vivant.html" dont le contenu est:
Je suis vivant.
Il servira au service "ldirectord.service" de vérifier qu'Apache est bien actif.
Service MariaDb-Galera
La configuration se base sur celle présentée dans l'article sur Galera - Cluster de MariaDB. La configuration de Garb sera abordée plus tard.
Configuration de MariaDb et de Galera
Nous prendrons la même configuration; nous mettrons la base de données dans le répertoire "/produc/mysql". Nous garderons aussi l'utilisation du répertoire "/produc/mysql.bat" et de son script "mysql.bat".
Seules deux options liées à Galera seront adaptées dans le fichier de configuration du serveur "/etc/my.cnf.d/mariadb-server.cnf".
Celle liée à l'ensemble des machines du cluster utilisant le réseau "192.168.2.0/24":
wsrep_cluster_address = "gcomm://192.168.2.75,192.168.2.71,192.168.2.72,192.168.2.73,192.168.2.74"
Et comme nous avons deux interfaces réseaux, il faut spécifier l'option "wsrep_node_address". Sur chaque machine, il faut mettre l'adresse IP de son interface réseau. Dans cet exemple, c'est celle de la machine "sv1.home.dom":
wsrep_node_address="192.168.2.71"
Configuration du service "checkgalera.service"
Nous utilisons le service "checkgaler.service" vu à l'article concernant la MariaDB/Galera - Solution d'automatisation de démarrage.
Il faut adapter le fichier "/manager/galera/hosts.txt":
sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom
Configuration du service Rsyncd
Le service précédent utilise le service Rsyncd (voir MariaDB/Galera - Solution d'automatisation de démarrage). ). La seule option à adapter dans le fichier "/etc/rsyncd.conf" est liée à la sécurité:
hosts allow = 192.168.2.71 192.168.2.72 192.168.2.73 192.168.2.74
Initialisation
Après la configuration, il est préférable de lancer une fois ces services avant d'aborder Pacemaker pour au moins initialiser correctement MariaDb. Pour initier au début le processus, on lance une première fois sur une machine la commande:
galera_new_cluster
Ensuite on peut lancer sur chaque machine le service "checkgalera.service":
systemctl start checkgalera.service
On les arrête ensuite.
Arrêt des services
Tous ces services que nous venons de configurer, nous avons dû les lancer pour effectuer les configurations.
Mais ce sera le rôle de Pacemaker de les gérer. Il faut donc les désactiver et les arrêter avant d'aborder la configuration de Pacemaker.
Sur toutes les machines, on effectue ces tâches:
umount /data systemctl stop httpd.service systemctl stop php-fpm.service systemctl stop glusterd.service systemctl stop mariadb.service systemctl stop rsyncd.service systemctl stop checkgalera.service systemctl disable httpd.service systemctl disable php-fpm.service systemctl disable glusterd.service systemctl disable mariadb.service systemctl disable rsyncd.service systemctl disable checkgalera.service
Configuration des paramètres et des services sur le router
Le router "sv5.home.dom" demande quelques configurations et services.
Activer le routage
Sur le router Linux "sv5.home.dom", il ne faut pas oublier d'activer le transfert inter-réseaux en ajoutant un fichier, par exemple "router.conf", dans le répertoire "/etc/sysctl.d". Ce fichier doit contenir la ligne:
net.ipv4.ip_forward = 1
On active cette fonctionnalité par un redfémarrage ou via la commande:
sysctl -p /etc/sysctl.d/router.conf
SSL
Nous avons configuré le service Web qui utilise le cryptage SSL et les certificats associés: HTTPS sur les serveurs Web. Pour valiser ces connexions, Ldirectord doit aussi valider leurs certificats.
Mais les certificats utilisés n'ont pas été validés par une autorité de certification officielle (CA). Il nous faut l'intégrer à la liste officielle du router comme expliqué dans l'article sur les Certificats sous Linux.
Dans l'article sur le Paramétrage des services en Failover, nous avions créé les certificats. Le certificat de l’autorité de certification (CA) se nomme "ca.home.crt". On va le copier dans le répertoire "/etc/pki/ca-trust/source/anchors" du router "cluster.home.dom". Ensuite on exécute la commande:
update-ca-trust
pour l'intégrer à la liste officielle des autorités de certification officielle (CA).
Configuration de Ldirectord
Le fichier de configuration se nomme "/etc/ha.d/ldirectord.cf". Il existe plusieurs types de configuration. Voici le contenu choisi:
emailalert="root"
emailalertfreq=3600
emailalertstatus=all
quiescent=yes
checkinterval=20
fork=yes
virtual=192.168.1.75:80
real=192.168.2.71:80 masq 65000
real=192.168.2.72:80 masq 65000
real=192.168.2.73:80 masq 65000
real=192.168.2.74:80 masq 65000
request="vivant.html"
receive="Je suis vivant."
checktype=negotiate
service=http
scheduler=lblcr
persistent=3600
protocol=tcp
checkport=80
virtual=192.168.1.75:443
real=192.168.2.71:443 masq 65000
real=192.168.2.72:443 masq 65000
real=192.168.2.73:443 masq 65000
real=192.168.2.74:443 masq 65000
request="vivant.html"
receive="Je suis vivant."
checktype=negotiate
service=https
scheduler=lblcr
persistent=3600
protocol=tcp
checkport=443
Cette configuration permet de répartir vers nos quatre serveurs Web, les protocoles HTTP et HTTPS en validant le contenu de la page "vivant.html".
Service Garb
Configuration du service Garb
Le fichier de paramétrage du service "garbd.service", "/etc/sysconfig/garb".
Voici son contenu:
GALERA_NODES="192.168.2.75,192.168.2.71,192.168.2.72,192.168.2.73,192.168.2.74" GALERA_GROUP="Home_cluster" LOG_FILE="/var/log/garb/garb.log"
En outre il faut définir le répertoire de travail de ce service dans le système Systemd.
Nous créons le sous-répertoire "garbd.service.d" dans le répertoire "/etc/systemd.system":
mkdir garbd.service.d
Dans ce répertoire, on crée un fichier qui permet d'ajouter une option définissant le répertoire de travail du service "garbd.service". On nomme ce fichier "workdir.conf" dont voici le contenu:
[Service] WorkingDirectory=/produc/garb
Comme on a modifié le paramétrage de Systemd, il faut le recharger:
systemctl daemon-reload
Il faut maintenant créer ce répertoire et lui donner la propriété à l'utilisateur "garb" qui lance le service "garbd.service":
mkdir /produc/garb chown -R garb:garb /produc/garb
Configuration du service "checkgarb.service"
Nous avons besoin du service Garb vu à l'article sur Galera - Cluster de MariaDB. Un système d'automatisation a été proposé dans l'article sut l'MariaDB/Galera - Solution d'automatisation de démarrage. Nous utiliserons le service "chackgarb.service".
Il faut adapter le fichier "/manager/galera/hosts.txt":
sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom
Arrêt des services
Tous ces services que nous venons de configurer, nous avons dû les lancer pour effectuer les configurations.
Mais ce sera le rôle de Pacemaker de les gérer. Il faut donc les désactiver et les arrêter avant d'aborder la configuration de Pacemaker.
Sur toutes les machines, on effectue ces tâches:
systemctl stop checkgarb.service systemctl stop ldirectord.service systemctl disable checkgarb.service systemctl disable ldirectord.service
Configuration de base de Pacemaker
La Configuration de base de Pacemaker doit être effectuée avec quelques modifications car nous avons cinq machines dans le cluster au lieu de deux. Nous allons passer rapidement en revue ces opérations.
Opérations locales
Sur chaque machine:
- le mot de passe de l'utilisateur "hacluster" est à implémenter. "Chasse4321Eau" pour mémoire.
- le service "pcsd.service" est à configurer et est lancé.
Initialisation du cluster
Pour initialiser le cluster, on effectue ces opérations sur une seule machine du cluster:
pcs host auth sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom sv5.home.dom -u hacluster -p Chasse4321Eau pcs cluster setup fo_cluster \ sv1.home.dom addr=192.168.2.71 sv2.home.dom addr=192.168.2.72 sv3.home.dom addr=192.168.2.73 \ sv4.home.dom addr=192.168.2.74 sv5.home.dom addr=192.168.2.75 \ transport knet ip_version=ipv4 link transport=udp mcastport=5420
Quorum
Pour la suite, nous sommes en présence d'un problème.
- Si nous ignorons la contrainte du "quorum" avec la commande:
pcs property set no-quorum-policy=ignore
le système continuera à tourner mais sans fonctionner si le router est arrêté ou si tous les serveurs Web le sont.
- Si nous maintenons la contrainte du "quorum" avec la commande, :
pcs property set no-quorum-policy=stop
- La solution vient du nombre de votes à attribuer à chaque machine et du nombre de votes attendus.
- Nous laissons un seul vote par serveur Web.
- Par contre, nous attribuons 4 voies au router.
- Le nombre de votes attendu sera de 8 votes.
- Donc le Quorum devient 5 au lieu de 3 (calcul: 8/2+1=5).
- Ce qui a pour conséquence que si le router s'arrête, il ne reste que 4 voies et donc le système s'arrête.
- De la même façon, si les 4 serveurs Web s'arrêtent, il ne reste aussi que 4 voies et donc le système s'arrête.
Modification de la configuration de Corosync
Pour atteindre ce quorum de cinq, il faut adapter sur chaque machine du cluster, le fichier "/etc/corosync/corosync.conf". La dernière commande a créé ce fichier.
Ce fichier devient pour les sections "nodelist" et "quorum":
nodelist {
node {
ring0_addr: 192.168.2.71
name: sv1.home.dom
nodeid: 1
quorum_votes: 1
}
node {
ring0_addr: 192.168.2.72
name: sv2.home.dom
nodeid: 2
quorum_votes: 1
}
node {
ring0_addr: 192.168.2.73
name: sv3.home.dom
nodeid: 3
quorum_votes: 1
}
node {
ring0_addr: 192.168.2.74
name: sv4.home.dom
nodeid: 4
quorum_votes: 1
}
node {
ring0_addr: 192.168.2.75
name: sv5.home.dom
nodeid: 5
quorum_votes: 4
}
}
quorum {
provider: corosync_votequorum
expected_votes: 8
}
Avec cette configuration, le "quorum" minimum sera de 5 (calcul: 8/2+1=5).
Notons que pour que cette modification soit effective, il faut arrêter puis redémarrer le cluster:
pcs cluster stop --all pcs cluster start --all
Fin de la configuration
Par la même occasion exécutez la fin de la configuration de base:
pcs property set stonith-enabled=false pcs property set no-quorum-policy=stop
La dernière spécifie que si le quorum n'est pas atteint, les ressources de Pacemaker sont arrêtées.
Configuration des ressources de Pacemaker
Script
On effectue la suite des commandes suivantes à partir d'une des machines du cluster. On peut les mettre dans un script.
#!/bin/bash pcs resource create ClusterGlusterd systemd:glusterd \ op monitor interval=20s clone pcs constraint location ClusterGlusterd-clone prefers sv1.home.dom=100 pcs constraint location ClusterGlusterd-clone prefers sv2.home.dom=100 pcs constraint location ClusterGlusterd-clone prefers sv3.home.dom=100 pcs constraint location ClusterGlusterd-clone prefers sv4.home.dom=100 pcs constraint location ClusterGlusterd-clone prefers sv5.home.dom=-INFINITY pcs resource create ClusterRsyncd systemd:rsyncd op monitor interval=30s clone pcs constraint order ClusterGlusterd-clone then start ClusterRsyncd-clone pcs constraint location ClusterRsyncd-clone prefers sv1.home.dom=100 pcs constraint location ClusterRsyncd-clone prefers sv2.home.dom=100 pcs constraint location ClusterRsyncd-clone prefers sv3.home.dom=100 pcs constraint location ClusterRsyncd-clone prefers sv4.home.dom=100 pcs constraint location ClusterRsyncd-clone prefers sv5.home.dom=-INFINITY pcs resource create ClusterCheckGalera systemd:checkgalera op monitor interval=30s clone pcs constraint order ClusterRsyncd-clone then start ClusterCheckGalera-clone pcs constraint location ClusterCheckGalera-clone prefers sv1.home.dom=100 pcs constraint location ClusterCheckGalera-clone prefers sv2.home.dom=100 pcs constraint location ClusterCheckGalera-clone prefers sv3.home.dom=100 pcs constraint location ClusterCheckGalera-clone prefers sv4.home.dom=100 pcs constraint location ClusterCheckGalera-clone prefers sv5.home.dom=-INFINITY pcs resource create ClusterCheckGarb systemd:checkgarb op monitor interval=30s pcs constraint order ClusterCheckGalera-clone then start ClusterCheckGarb pcs constraint location ClusterCheckGarb prefers sv1.home.dom=-INFINITY pcs constraint location ClusterCheckGarb prefers sv2.home.dom=-INFINITY pcs constraint location ClusterCheckGarb prefers sv3.home.dom=-INFINITY pcs constraint location ClusterCheckGarb prefers sv4.home.dom=-INFINITY pcs constraint location ClusterCheckGarb prefers sv5.home.dom=INFINITY pcs resource create ClusterFsWeb ocf:heartbeat:Filesystem \ device="localhost:/diskgfs1" \ directory="/data" fstype="glusterfs" \ "options=defaults,_netdev" \ op monitor interval=20s on-fail=stop clone pcs constraint order ClusterCheckGarb then start ClusterFsWeb-clone pcs constraint location ClusterFsWeb-clone prefers sv1.home.dom=100 pcs constraint location ClusterFsWeb-clone prefers sv2.home.dom=100 pcs constraint location ClusterFsWeb-clone prefers sv3.home.dom=100 pcs constraint location ClusterFsWeb-clone prefers sv4.home.dom=100 pcs constraint location ClusterFsWeb-clone prefers sv5.home.dom=-INFINITY pcs resource create ClusterHttpd systemd:httpd op monitor interval=30s clone pcs constraint order ClusterFsWeb-clone then start ClusterHttpd-clone pcs constraint location ClusterHttpd-clone prefers sv1.home.dom=100 pcs constraint location ClusterHttpd-clone prefers sv2.home.dom=100 pcs constraint location ClusterHttpd-clone prefers sv3.home.dom=100 pcs constraint location ClusterHttpd-clone prefers sv4.home.dom=100 pcs constraint location ClusterHttpd-clone prefers sv5.home.dom=-INFINITY pcs resource create ClusterPhp systemd:php-fpm op monitor interval=30s clone pcs constraint order ClusterHttpd-clone then start ClusterPhp-clone pcs constraint location ClusterPhp-clone prefers sv1.home.dom=100 pcs constraint location ClusterPhp-clone prefers sv2.home.dom=100 pcs constraint location ClusterPhp-clone prefers sv3.home.dom=100 pcs constraint location ClusterPhp-clone prefers sv4.home.dom=100 pcs constraint location ClusterPhp-clone prefers sv5.home.dom=-INFINITY pcs resource create ClusterMailTo ocf:heartbeat:MailTo email=root subject="FailOver_Home" op monitor interval=30s clone pcs constraint order ClusterPhp-clone then start ClusterMailTo-clone pcs resource create ClusterLdirectord systemd:ldirectord op monitor interval=30s pcs constraint order ClusterPhp-clone then start ClusterLdirectord pcs constraint location ClusterLdirectord prefers sv1.home.dom=-INFINITY pcs constraint location ClusterLdirectord prefers sv2.home.dom=-INFINITY pcs constraint location ClusterLdirectord prefers sv3.home.dom=-INFINITY pcs constraint location ClusterLdirectord prefers sv4.home.dom=-INFINITY pcs constraint location ClusterLdirectord prefers sv5.home.dom=INFINITY
Ajout des ressources clonées
La majorité des ressources sont clonées. En effet les quatre serveurs WEB ont la même configuration. Mais ces ressources ne doivent pas s'exécuter sur le router d'où la contrainte de localisation dont le score est "-INFINITY" sur le router.
- La ressource "ClusterGlusterd" va activer le service GlusterFs configuré ci-dessus.
- La ressource "ClusterRsyncd" va activer le service Rsync configuré ci-dessus.
- La ressource "ClusterCheckGalera" va activer le service CheckGalera configuré ci-dessus qui lancera le service MariaDb.
- La ressource "ClusterFsWeb" va monter le volume "diskgfs1" local sur le répertoire "/data".
- La ressource "ClusterHttpd" va activer le service Apache configurée ci-dessus.
- La ressource "ClusterPhp" va activer le service Php.
Par contre la ressource "ClusterMailTo" doit s'exécuter sur toutes les machines.
Ajout des ressources localisées
Les deux dernières ressources "ClusterLdirectord" et "ClusterCheckGarb" ne doivent s'exécuter que sur une seule machine: le router d'où la contrainte de localisation dont le score est "-INFINITY" sur les serveurs Web.
Ordre
Nous avons intercalé le lancement de Rsyncd, MariaDb et Garbd entre le service Glusterd et le montage du volume afin de laisser à GlusterFs le temps de se lancer.
Nous avons ordonné l'ordre des lancements de ces services.
Remarque
Lors de l'étape d'exécution du script, vous aurez une erreur en liaison avec le montage de l'espace disque "/data" sur le router. C'est normal car le montage se fait localement, il n'y a pas de serveur GlusterFs et la contrainte de non-localisation n'est pas encore configurée. La commande suivante permet de l'effacer:
pcs resource cleanup ClusterFsWeb
Cette erreur ne se représente plus par la suite.
Statut
Après cette opération, l'état du cluster peut être visualisé par la commande:
crm_mon -1rnf
qui donne dans le cas des cinq machines actives:
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: sv1.home.dom (version 2.1.6-4.fc38-6fdc9deea29) - partition with quorum
* Last updated: Thu Jun 22 17:25:00 2023 on sv1.home.dom
* Last change: Thu Jun 22 17:24:53 2023 by root via cibadmin on sv1.home.dom
* 5 nodes configured
* 37 resource instances configured
Node List:
* Node sv1.home.dom: online:
* Resources:
* ClusterGlusterd (systemd:glusterd): Started
* ClusterRsyncd (systemd:rsyncd): Started
* ClusterCheckGalera (systemd:checkgalera): Started
* ClusterFsWeb (ocf::heartbeat:Filesystem): Started
* ClusterHttpd (systemd:httpd): Started
* ClusterPhp (systemd:php-fpm): Started
* ClusterMailTo (ocf::heartbeat:MailTo): Started
* Node sv2.home.dom: online:
* Resources:
* ClusterGlusterd (systemd:glusterd): Started
* ClusterRsyncd (systemd:rsyncd): Started
* ClusterCheckGalera (systemd:checkgalera): Started
* ClusterFsWeb (ocf::heartbeat:Filesystem): Started
* ClusterHttpd (systemd:httpd): Started
* ClusterPhp (systemd:php-fpm): Started
* ClusterMailTo (ocf::heartbeat:MailTo): Started
* Node sv3.home.dom: online:
* Resources:
* ClusterGlusterd (systemd:glusterd): Started
* ClusterRsyncd (systemd:rsyncd): Started
* ClusterCheckGalera (systemd:checkgalera): Started
* ClusterFsWeb (ocf::heartbeat:Filesystem): Started
* ClusterHttpd (systemd:httpd): Started
* ClusterPhp (systemd:php-fpm): Started
* ClusterMailTo (ocf::heartbeat:MailTo): Started
* Node sv4.home.dom: online:
* Resources:
* ClusterGlusterd (systemd:glusterd): Started
* ClusterRsyncd (systemd:rsyncd): Started
* ClusterCheckGalera (systemd:checkgalera): Started
* ClusterFsWeb (ocf::heartbeat:Filesystem): Started
* ClusterHttpd (systemd:httpd): Started
* ClusterPhp (systemd:php-fpm): Started
* ClusterMailTo (ocf::heartbeat:MailTo): Started
* Node sv5.home.dom: online:
* Resources:
* ClusterCheckGarb (systemd:checkgarb): Started
* ClusterMailTo (ocf::heartbeat:MailTo): Started
* ClusterLdirectord (systemd:ldirectord): Started
Inactive Resources:
* Clone Set: ClusterGlusterd-clone [ClusterGlusterd]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Stopped: [ sv5.home.dom ]
* Clone Set: ClusterRsyncd-clone [ClusterRsyncd]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Stopped: [ sv5.home.dom ]
* Clone Set: ClusterCheckGalera-clone [ClusterCheckGalera]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Stopped: [ sv5.home.dom ]
* Clone Set: ClusterFsWeb-clone [ClusterFsWeb]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Stopped: [ sv5.home.dom ]
* Clone Set: ClusterHttpd-clone [ClusterHttpd]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Stopped: [ sv5.home.dom ]
* Clone Set: ClusterPhp-clone [ClusterPhp]:
* Started: [ sv1.home.dom sv2.home.dom sv3.home.dom sv4.home.dom ]
* Stopped: [ sv5.home.dom ]
Migration Summary:
Client
Pour atteindre le site Web, le client doit introduire l'URL: https://cluster.home.dom/
Cette machine "cluster.home.dom" doit être liée à l'adresse IP "192.168.1.75" via le fichier "hosts" ou le serveur DNS.
→ retour au menu de la Haute disponibilité